

Kasvojen ja tunteiden tunnistusjärjestelmän tuottamien tulosten laatu ja tarkkuus riippuu tiedoista. Mitä tarkempia ja laajempia tietoja on, sitä paremmat ovat tekoälyohjelman mahdollisuudet tunnistaa ja havaita tunteita.

Tekoälyllä on vakuutusalan etuja, mikäli yritykset ymmärtävät sen toteutuksen. Kun tehtävät, kuten korvausvaatimusten käsittely, palkkion asettaminen ja vahinkojen havaitseminen, on virtaviivaistettu, se voi myös auttaa asiakaspalvelussa ja lisää yleistä tyytyväisyyttä.

Tietojen tunnistamisen poistaminen on ratkaisevan tärkeää henkilökohtaisten tunnistetietojen turvaamiseksi terveydenhuollossa, ja se noudattaa säädösvaatimuksia, kuten HIPAA ja GDPR. Esitellyt työkalut, kuten IBM InfoSphere Optim, Google Healthcare API, AWS Comprehend Medical, Shaip ja Private-AI, tarjoavat erilaisia ratkaisuja tehokkaaseen tietojen peittämiseen.

Generatiivisella tekoälyllä on joitain tehokkaita ominaisuuksia ja toimintoja, jotka on asetettu päivittämään asiakaspalvelun tukijärjestelmiä. Jos se pystyy ratkaisemaan asiakkaan ongelmat nopeasti, generatiivinen tekoäly voi myös korvata agentit ensiapuhenkilöinä ja kommunikoida asiakkaiden kanssa kuin ihminen.

Tietojen tunnistamisen poistaminen on kriittinen toimenpide, jolla varmistetaan henkilötietojen luvaton pääsy ja laiton käyttö. Erityisen tärkeä terveydenhuollon tietojen kannalta tämä prosessi varmistaa, että henkilökohtaisia tunnistetietoja ei päädy muiden kuin tietoihin läheisesti liittyvien henkilöiden käsiin.

Keskusteleva ja luova tekoäly muuttaa maailmaamme ainutlaatuisilla tavoilla. Keskusteleva tekoäly tekee koneille puhumisesta helppoa ja hyödyllistä, mikä parantaa asiakastukea ja terveydenhuoltopalveluita. Generatiivinen tekoäly on toisaalta luova voimanpesä. Se keksii uutta, omaperäistä sisältöä taiteessa, musiikissa ja muussa. Näiden tekoälytyyppien ymmärtäminen on avain älykkääseen liiketoimintaan, etiikkaan ja innovaatiopäätöksiin.

Puheteknologiat ovat vielä suhteellisen uusia teknologioita ja teemme edelleen töitä saadaksemme hyvän käsityksen niiden kanssa tarjottavista ratkaisuista. Aikaherkässä terveydenhuollon ympäristössä tehokkuus ja tarkkuus ovat ensiarvoisen tärkeitä.

Generatiivinen tekoäly muokkaa pankki- ja rahoituspalveluiden maisemaa, tuo tehokkuutta, parantaa turvallisuutta ja tarjoaa yksilöllisiä kokemuksia sekä asiakkaille että instituutioille. Kun teknologia kehittyy edelleen, sen vaikutus rahoitusalaan todennäköisesti kasvaa ja aloittaa uuden innovaation ja optimoinnin aikakauden.

Natural Language Processingin (NLP) hyödyntäminen terveydenhuolto- ja lääketeollisuudessa perustuu vahvasti jäsentämättömän datan analysointiin. Asianmukaisten tietojen avulla terveydenhuoltoorganisaatiot voivat saada useita etuja ja tarjota parempia terveydenhuoltopalveluita potilaille.

Käyttäjien luoman sisällön määrä ja tiheys kasvavat tulevina vuosina. Asiakkailla on nykyään käytettävissään innovatiivisia työkaluja, joiden avulla he tietävät kaiken brändistä. Kun vuorovaikutus olemassa olevien, uusien ja potentiaalisten asiakkaiden kanssa on olennaista brändille, sisällön seuranta ja moderointi on avainasemassa positiivisen kuvan luomisessa.

Tehokas tietojen merkitseminen on olennainen osa haun osuvuuden parantamista. Sähköisen kaupankäynnin alustat ja yritykset hyötyvät eniten tietomerkinnöistä, koska niiden on tuotava tuotteensa esiin hakutuloksissa, mikä johtaa myynnin ja tulojen kasvuun.

Luonnollisen kielen käsittely (NLP) on käynnistänyt tiedonkeruun ja -analyysin vallankumouksen kaikilla toimialoilla. Tämän tekniikan monipuolisuus kehittyy myös tarjoamaan parempia ratkaisuja ja uusia sovelluksia. NLP:n käyttö rahoituksessa ei rajoitu edellä mainitsemiimme sovelluksiin. Ajan myötä voimme käyttää tätä tekniikkaa ja sen tekniikoita entistä monimutkaisempiin tehtäviin ja operaatioihin.

Tekoälyn sovellusten ytimessä terveydenhuollossa on data ja sen oikea analyysi. Käyttämällä näitä terveydenhuollon ammattilaisten toimittamia tietoja, tekoälytyökalut ja -tekniikat voivat tarjota parempia terveydenhuoltoratkaisuja diagnoosin, hoidon, ennustamisen, reseptien ja kuvantamisen suhteen.

Nimettyjen entiteettien tunnistus on elintärkeä tekniikka, joka tasoittaa tietä edistyneelle tekstin ymmärtämiselle koneellisesti. Vaikka avoimen lähdekoodin tietojoukoilla on etuja ja haittoja, ne ovat tärkeitä NER-mallien koulutuksessa ja hienosäädössä. Näiden resurssien järkevä valinta ja soveltaminen voi parantaa merkittävästi NLP-projektien tuloksia.

Generatiivinen tekoäly tarjoaa merkittäviä etuja, kuten tehokkuutta, skaalautuvuutta ja personointia, sillä se pystyy luomaan monipuolista sisältöä. Haasteet, kuten laadunvalvonta, luovuuden rajoitukset ja eettiset huolenaiheet, vaativat kuitenkin huolellista huomiota.

Generatiivinen tekoäly on jännittävä raja, joka määrittelee uudelleen teknologian ja luovuuden rajat. Ihmisen kaltaisen tekstin luomisesta realististen kuvien luomiseen, koodikehityksen tehostamiseen ja jopa ainutlaatuisten äänilähtöjen simuloimiseen, sen todelliset sovellukset ovat yhtä monipuolisia kuin muuttaviakin.

Koneoppimisen ja tekoälyn sovellukset kliinisen tiedon analysoinnissa ovat laajoja ja uraauurtavia. Ne tarjoavat valtavan potentiaalin potilaan hoidon uudistamiseen, lääketieteellisen tutkimuksen parantamiseen ja aikaisempien ja tarkempien diagnoosien tarjoamiseen.

Shaip on edelläkävijä tarjoamassa huippuluokan terveydenhuolto- ja lääketieteellistä dataa, joka on välttämätöntä tekoäly- ja koneoppimismalleille. Jos olet aloittamassa terveydenhuollon tekoälyprojektia tai tarvitset erityisiä lääketieteellisiä tietoja, Shaip on täydellinen kumppani.

Ääniavustajat eivät ole enää uutuus; niistä on nopeasti tulossa elintärkeitä päivittäisessä digitaalisessa vuorovaikutuksessamme. Monikielisen puheavustajan nousu lupaa olla merkittävä harppaus eteenpäin, joka murtaa kielimuurit ja edistää maailmanlaajuista yhteyksiä.
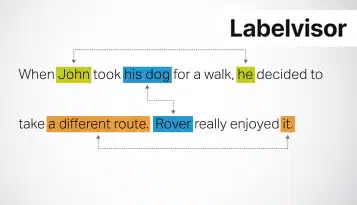
Asiakirjan merkintä on olennainen rakennuspalikka tekoälyssä, koneoppimisessa ja luonnollisen kielen käsittelyssä. Se parantaa tekoälyjärjestelmien ymmärrystä ja prosessointikykyä, tehostaa tiedonpoistoa ja edistää automaatiota eri aloilla.

Kuten olemme tutkineet yllä olevissa esimerkeissä, tunneanalyysillä on huomattavaa potentiaalia useissa eri sovelluksissa aina asiakaspalvelusta politiikkaan. Sen avulla organisaatiot voivat vapauttaa subjektiivisen datan voiman ja muuttaa jäsentelemättömän tekstin käyttökelpoisiksi oivalluksiksi.

Terveydenhuollon tekoälyn tulevaisuus on täynnä lupauksia ja potentiaalia, ja vuoden 2023 nousevat trendit osoittavat muutosta potilashoidon toiminnassa.

Luonnollisen kielenkäsittelyn käyttötapaukset terveydenhuollossa ovat laajat ja muuttavat. Valjastamalla tekoälyn, koneoppimisen ja keskustelun tekoälyn tehoja NLP mullistaa terveydenhuollon ammattilaisten suhtautumisen potilaiden hoitoon. Se tehostaa lääketieteellisiä työnkulkuja ja parantaa potilaiden kokonaistuloksia.
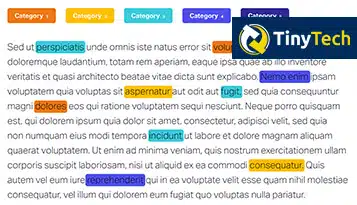
Tekoälypohjaisen kokonaisuuden poiminnan käyttöönotto on johtanut merkittäviin edistysaskeleihin eri aloilla terveydenhuollosta sähköiseen kaupankäyntiin, parantamaan päätöksentekoa, virtaviivaistamaan prosesseja ja parantamaan asiakaskokemusta.

Tunteidentunnistustekniikka on tehokas työkalu, joka voi parantaa ymmärrystämme ihmisten tunteista ja auttaa meitä luomaan yksilöllisiä kokemuksia eri aloilla, kuten terveydenhuollossa, koulutuksessa ja markkinoinnissa.

Kaiken kaikkiaan terveydenhuollon ala on täynnä potilaita ja lääkäreitä, jotka ovat motivoituneita vaikuttamaan ihmisten elämään eri puolilla maailmaa. Pääsy suuriin tietokokonaisuuksiin on yksisuuntainen tekoäly tulee jatkossakin todistamaan olevansa lääketieteen tulevaisuus. Sekä tutkijoiden että kehittäjien tehtävänä on hyödyntää näitä ainutlaatuisia tietokokonaisuuksia parantaaksemme ymmärrystämme kliinisistä tutkimuksista ja potilaiden hoidosta, kun siirrymme kohti entistä enemmän yhteneväistä tulevaisuutta kaikille.

Seuraavat viisi vuotta tuovat mukanaan virtaviivaisempia tekoälykokemuksia, turvaominaisuuksia, jotka parantavat näitä vuorovaikutuksia, ja paljon muuta. Keskustelevat tekoälytrendit ovat lähivuosina kirkkaampia ja helpommin saavutettavissa kuin koskaan ennen.

Muutokset jatkuvat, mikä johtaa pankkikelpoisempaan, kannattavampaan tulevaisuuteen, joka tarjoaa paremman käyttökokemuksen. Näiden muutosten ja muiden yritysten virheistä oppimisen ansiosta BFSI-sektori jatkaa nopeaa etenemistä kohti kasvojentunnistuksen käyttöä – tehokkaampaa ja turvallisempaa lopputavoitetta kaikille osapuolille.

Puhehaku on kasvava teknologia-ala. Se ottaa hitaasti mutta varmasti suuria harppauksia, kun se pystyy paremmin AI:n, luonnollisen kielen käsittelyn ja koneoppimisen avulla. Nykyinen tekoälytyyppi ei ole tunteva; nämä puheavustajat ovat työkaluja, jotka tekevät elämästämme parempaa, yksinkertaisempaa ja tehokkaampaa.
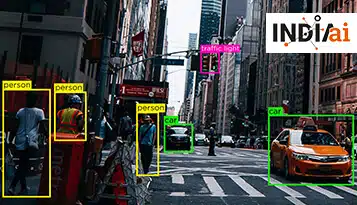
Tietojen merkintäpalvelut auttavat yrityksiä muuttamaan tiedot, joissa ei ole tunnisteita tai tunnisteita, tiedoiksi, joilla on. He käyttävät usein ihmisten työryhmää tai koneoppimista merkitsemään yritysten heille antamia tietojoukkoja.

Äänentunnistustekniikka voi mahdollisesti mullistaa terveydenhuoltoalan useilla tavoilla. Äänentunnistustekniikka voi auttaa terveydenhuollon tarjoajia tarjoamaan parempaa hoitoa mahdollistamalla nopeamman ja tarkemman dokumentoinnin, vähentämällä virheiden riskiä ja parantamalla potilaiden sitoutumista.

Vakuutusalalla on paljon dataa, mutta se on niin sekavaa, että haku on lähes mahdotonta. Vakuutusala on digitalisoitava – ja nyt se voidaan tehdä. Kun OCR on paikallaan, tietojen kerääminen ja lajittelu on yhtä helppoa kuin kuvan ottaminen tai muutaman sanan kirjoittaminen.

Pankeilla on positiivinen kokemus tekoälytekniikoiden käyttöönotosta. Tämä perustuu haastatteluihin yritysten kanssa, jotka jo käyttävät tekoälyä liiketoimintaprosesseissaan. Pankkien tulee ottaa tekoäly järjestelmiinsä niin kauan kuin turvatoimia on rakennettu varmistamaan asiakkaiden tietojen turvallisuus ja eettiset standardit, joita voidaan säännellä automaattisesti.

Koneoppimisen vaikutus puhelinpalvelumarkkinoilla on todellinen ja mitattavissa. Reaaliaikainen tiedonkeruu ja koneoppiminen on yhdistetty entistä tehokkaampien puhelinkeskusten mahdollistamiseksi. Lisäksi puhepohjaiset ratkaisut ovat lisääntyneet kaikkialla Pohjois-Amerikassa ja jatkavat leviämistä ympäri maailmaa.

Äänentunnistusteknologiasta on tulossa yhä tärkeämpi terveydenhuollossa, ja lääkärit ja sairaanhoitajat luottavat siihen yhä enemmän monien ammatillisten tehtäviensä hoitamisessa. Vaikka monia kysymyksiä on vielä ratkaistava, ennen kuin näemme tämän tekniikan laajan käytön sairaaloissa, kliinisissä ympäristöissä ja lääkärin vastaanotoissa, varhaiset merkit viittaavat siihen, että lupaus on merkittävä.
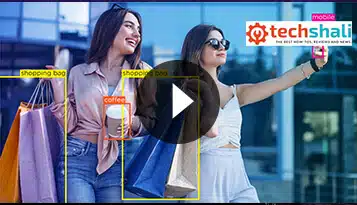
Videomerkintäteknologian tarkoituksena on pitää vähittäiskaupan tekoälyjärjestelmät ja asiakkaat turvassa. Videon huomautusohjelmisto on loistava tapa tehdä tämä antamalla ihmisten nopeasti ja helposti hälyttää viranomaisia, kun he havaitsevat jotain epäilyttävää vähittäiskaupassa. auttaa tekoälyjärjestelmiä oppimaan aiemmista kokemuksista, jotta ne voivat räätälöidä vastauksensa niin, että ne tuntevat paremmin normaalin käyttäytymisen.

Kasvojentunnistuksen käyttötapaukset voivat tehdä ihmeitä tietoja tallennettaessa ja haettaessa, mutta niissä on myös kiehtova eettinen ongelma. Onko järkevää käyttää tällaista tekniikkaa? Jotkut ihmiset uskovat, että vastaus on "ei", erityisesti mitä tulee kasvojentunnistuksen yksityisyyden loukkaamiseen. Toiset mainitsevat näiden uusien työkalujen käytön, minkä vuoksi tätä tekniikkaa ei ehkä kannata välttää hinnalla millä hyvänsä.

Tekoäly muuttaa tapaamme olla vuorovaikutuksessa teknologian kanssa. Kun olet tottunut keskustelulliseen tekoälyyn ja siitä tulee saumaton osa elämääsi, ihmettelet, kuinka olisit koskaan pärjännyt ilman sitä.

Mukautetut herätyssanat voivat auttaa brändisi personoinnissa ja erottaa sen kilpailijoista. On monia tekijöitä, jotka on otettava huomioon valittaessa mukautettua herätyssanaa. Mutta jos haluat erottua joukosta nykypäivän kilpailevassa yritysmaailmassa, kannattaa panostaa siihen, että ääniavustajasi kuulostaa ainutlaatuiselta.

Uudet puhetekniikan edistysaskeleet ovat tulleet jäädäkseen. Niiden suosio vain kasvaa, joten nyt on täydellinen aika päästä kärjestä ja alkaa luoda innovatiivisia äänikokemuksia kuljettajille. Kun autonvalmistajat integroivat puheentunnistuksen autoihinsa, tämä avaa tekniikalle ja sen käyttäjille uuden mahdollisuuksien maailman.

On selvää, että ruoan tekoälyllä on valtava vaikutus siihen, miten syömme. Pikaruokaketjujen pyrkimyksestä räätälöidympiin menuihin lukuisiin uusiin, innovatiivisiin ravintoloihin teknologialla on lukemattomia mahdollisuuksia yksinkertaistaa ruokailukokemuksiamme ja parantaa ruokien laatua. Tekoälyn ja koneoppimisalgoritmien kehittymisen myötä voimme odottaa älykkään ruoan tekoälyn vaikuttavan myönteisesti terveyteemme ja elintarvikejärjestelmämme yleiseen ekologiseen vaikutukseen.

Yhteenvetona voidaan todeta, että semanttinen segmentointi on tärkeä osa syväoppimisalgoritmeista, joita käytetään tehostamaan tietokonenäön kehitystä. Semanttinen segmentointi etenee edelleen monissa näihin liittyvissä alakategorioissa, objektien havaitsemisessa, luokittelussa ja lokalisoinnissa.

Kaiken kaikkiaan tehokkaan puheentunnistusjärjestelmän pitäisi olla helppo asentaa ja käyttää erilaisissa tilanteissa samalla, kun sillä saavutetaan tarkkoja tuloksia ilman käyttäjän turhautumista.

Älykodin datan rakentaminen vaatii joukon prosesseja, jotka varmistavat, että koneoppimisalgoritmi toimii ja käsittelee dataa ilman häiriöitä.

Vakuutusala on perinteisesti ollut konservatiivinen teknologian kehityksen suhteen ja epäröinyt ottaa käyttöön uusia teknologioita. Ajat kuitenkin muuttuvat, ja tekoäly (AI) saa paljon huomiota vakuutusyhtiöiltä, jotka ovat alkaneet ymmärtää, kuinka tärkeä rooli tekoälyllä voi olla heidän toiminnassaan.

Tiedonkeruu on prosessi, jossa kerätään, analysoidaan ja mitataan tarkkoja tietoja erilaisista järjestelmistä käytettäväksi liiketoimintaprosessien päätöksenteossa, puheprojekteissa ja tutkimuksessa.

Pankkitoiminta ei ole sitä mitä se oli. Useimmat meistä tarvitsevat nopeita, tehokkaita, virheettömiä pankkipalveluita, jotka ovat vaivatonta ja mikä tärkeintä, luotettavia. On vain järkevää siirtyä digitaalisiin pankkikanaviin, jotka voivat tarjota näitä asioita. Kuten käy ilmi, tekoälyn (AI) ja koneoppimisen (ML) avulla toimivat virtuaaliassistentit voivat tehdä juuri sen.

Oletko koskaan joutunut kääntämään tärkeitä sähköposteja toiselle kielelle? Jos näin on, sinun on turhauttavaa tietää, että jonkun sähköpostin vastauspalvelu ei pysty kääntämään sähköpostejasi puolestasi nopeasti. Tämä voi olla erityisen turhauttavaa, jos viestintä on avainasemassa mille tahansa organisaatiolle.

Termejä chatbot ja virtuaaliset avustajat käytetään keskustelujen luomiseen käyttämällä automaatiokykyä inhimillisellä kosketuksella. Autonomisella resoluutiolla chatbotit ja virtuaaliassistentit nopeuttavat myös työntekijöiden ja asiakkaiden kokemusta.

Usein yhdeksi tekstiluokittelun alialueista pidetty liian yksinkertaistettu versio dokumenttien luokittelusta tarkoittaa asiakirjojen merkitsemistä ja asettamista ennalta määritettyihin luokkiin – helpon ylläpidon ja tehokkaan löytämisen vuoksi.

Hei Siri, voitko etsiä minulta hyvää blogitekstiä, joka sisältää tärkeimmät keskustelun tekoälytrendit. Tai Alexa, voitko soittaa minulle kappaleen, joka vie ajatukseni pois arkipäiväisistä tehtävistä. No, nämä eivät ole vain retoriikkaa, vaan tavallisia salikeskusteluja, jotka vahvistavat Conversational AI -konseptin kokonaisvaikutuksen.

OCR tai optinen merkintunnistus on hauska tapa lukea ja ymmärtää asiakirjoja. Mutta miksi siinä on edes järkeä? Otetaan selvää. Mutta ennen kuin jatkamme, meidän on käärittävä päämme vähemmän yleiseen koneoppimistermiin: RPA (Robotic Process Automation).

Kova totuus on, että keräämiesi harjoitustietojen laatu määrää puheentunnistusmallisi tai jopa laitteen laadun. Siksi on tarpeen ottaa yhteyttä kokeneisiin datantoimittajiin, jotta voit purjehtia prosessin läpi ilman paljon vaivaa, varsinkin kun mallin tai asianomaisten algoritmien koulutus vaatii keräämistä, huomautuksia ja muita taitavia strategioita.

Koneisiin syötetyllä kyvyllä, joka tekee niistä vuorovaikutuksen mahdollisimman inhimillisimmällä tavalla, on erilainen korkea. Silti kysymys jää, kuinka keskustelullinen tekoäly toimii reaaliajassa ja millainen teknologia tukee sen olemassaoloa.

Kuten nimestä voi päätellä, synteettinen data on keinotekoisesti tuotettua dataa todellisten tapahtumien luomisen sijaan. Markkinoinnin, sosiaalisen median, terveydenhuollon, rahoituksen ja turvallisuuden alalla synteettinen data auttaa rakentamaan innovatiivisempia ratkaisuja.

Kun puhumme optisesta merkintunnistuksesta (OCR), se on tekoälyn (AI) ala, joka liittyy erityisesti tietokonenäön ja hahmontunnistukseen. OCR viittaa tiedon poimimiseen useista tietomuodoista, kuten kuvista, pdf-tiedostoista, käsinkirjoitetuista muistiinpanoista ja skannatuista asiakirjoista, ja muuntaa ne digitaaliseen muotoon jatkokäsittelyä varten.

Kuljettajan valvontajärjestelmä on edistyksellinen turvaominaisuus, joka käyttää kojelautaan kiinnitettyä kameraa kuljettajan valppauden ja uneliaisuuden seuraamiseen. Jos kuljettaja on unelias ja hajamielinen, kuljettajan valvontajärjestelmä antaa hälytyksen ja suosittelee tauon ottamista.

Natural Language Processing on tekoälyn alakenttä, joka pystyy murtamaan ihmiskielen ja syöttämään sen periaatteet älykkäille malleille. Oletko aikeissa käyttää NLP:tä malliharjoitteluteknologiana? Lue eteenpäin saadaksesi tietoa haasteista ja ratkaisuista niiden korjaamiseen.

Tämän lisäksi Conversational AI oppii jatkuvasti aikaisemmista kokemuksista käyttämällä koneoppimistietosarjoja tarjotakseen reaaliaikaista tietoa ja erinomaista asiakaspalvelua. Lisäksi Conversational AI ei vain ymmärrä manuaalisesti ja vastaa kyselyihimme, vaan se voidaan myös yhdistää muihin tekoälyteknologioihin, kuten hakuun ja visioon prosessin nopeuttamiseksi.

Kuvantunnistus on ohjelmiston kyky tunnistaa kuvista esineitä, paikkoja, ihmisiä ja toimia. Koneoppimistietojoukkojen avulla yritykset voivat tunnistaa ja luokitella kohteita useisiin luokkiin kuvantunnistuksen avulla.

Tekoäly tekee koneista älykkäämpiä, piste! Kuitenkin tapa, jolla he tekevät sen, on yhtä erilainen ja kiehtova kuin kyseinen vertikaali. Esimerkiksi Natural Language Processingin kaltaiset tavat ovat hyödyllisiä, jos suunnittelet ja kehität älykkäitä chatbotteja ja digitaalisia avustajia. Vastaavasti, jos haluat tehdä vakuutusalasta läpinäkyvämpää ja mukautuvampaa käyttäjiä kohtaan, Computer Vision on tekoälyn aliverkkotunnus, johon sinun on keskityttävä.

Voivatko koneet havaita tunteita yksinkertaisesti skannaamalla kasvoja? Hyvä uutinen on, että he voivat. Ja huono uutinen on, että markkinoilla on vielä pitkä matka ennen kuin ne muuttuvat valtavirtaan. Tiesulut ja adoptiohaasteet eivät kuitenkaan estä tekoälyevankelisteja ottamasta "Emotion Detectionia" tekoälykartalle – varsin aggressiivisesti.

Computer Vision ei ole yhtä laajalle levinnyt kuin muut tekoälysovellukset, kuten Natural Language Processing. Silti se on hitaasti nousemassa riveihin, mikä tekee vuodesta 2022 jännittävän vuoden laajemmalle adoptiolle. Tässä on joitain trendikkäitä tietokonenäköpotentiaalia (enimmäkseen toimialueita), joita yritysten odotetaan tutkivan paremmin vuonna 2022.

Yritykset ympäri maailmaa ovat siirtymässä paperipohjaisista asiakirjoista digitaaliseen tietojenkäsittelyyn. Mutta mikä on OCR? Kuinka se toimii? Ja missä liiketoimintaprosessissa sitä voidaan hyödyntää sen hyötyjen hyödyntämiseksi? Katsotaanpa tässä artikkelissa, mitä etuja OCR tuo pöytään.

Vastaus on automaattinen puheentunnistus (ASR). Se on valtava askel muuttaa puhuttu sana kirjoitettuun muotoon. Automaattinen puheentunnistus (ASR) on trendi, jonka on määrä tehdä melua vuonna 2022. Ja puheavustajien kasvu johtuu sisäänrakennetuista puheavustajaälypuhelimista ja älypuhelimista, kuten Alexa.
Etsitkö aivoja parhaiden tekoälymallien takaa? No, kumarra Data Annotaattorit. Vaikka datamerkinnät ovat keskeisessä asemassa valmisteltaessa resursseja, jotka liittyvät jokaiseen tekoälyyn perustuvaan toimialaan, tutkimme konseptia ja opimme lisää merkintöjen päähenkilöistä Healthcare AI:n näkökulmasta.

Ja eikö olekin kiehtovaa, jos ostajat maksavat laskun uloskirjautumisen yhteydessä pelkällä kasvolla, eivät millään kortilla tai lompakolla? Kasvojentunnistuksen avulla jälleenmyyjät voivat analysoida ostajien mielialoja ja mieltymyksiä aiempien ostosten perusteella.

Digitaalisten maksujen lisääntyessä ympäri maailmaa kuinka rahoitusorganisaatiot voivat varmistaa myynnin maksimaalisen konversion ja maksujen hyväksymisen sekä minimoida riskialtistuksen? Kuulostaako hälyttävältä? Rahoitusalalla, joka on erittäin riippuvainen tietojenkäsittelystä ja tiedosta marginaalisen edun säilyttäminen ja asiakkaiden luonnollisen vivahteen ymmärtäminen oikea-aikaisen ratkaisun tarjoamiseksi, vaatii tekoälyyn liittyvää teknologiaa.

Droonit ovat käyttökelpoinen tiedonkeruuväline ja tarjoavat reaaliaikaista tietoa. Tietojen analysointi mahdollistaa siltojen, kaivostoiminnan ja sääennusteiden tarkastamisen helpommin.

Call Centerin mielipideanalyysi on tietojen käsittelyä tunnistamalla asiakkaan kontekstin luonnolliset vivahteet ja analysoimalla dataa, jotta asiakaspalvelusta tulee empaattisempaa.

No, ensimmäinen syy ei vaadi vahvistusta. Koneoppimisprojektit vaativat algoritmeja, tiedonhankintaa, laadukasta huomautusta ja muita monimutkaisia asioita, joista on huolehdittava.

Tekoälyn osana NLP:n tarkoituksena on saada koneet reagoimaan ihmiskielelle. Teknisestä näkökulmasta NLP, aivan sopivasti, käyttää tietojenkäsittelytiedettä, lingvistiikkaa, algoritmeja ja yleistä kielirakennetta tehdäkseen koneista älykkäitä. Ennakoivat ja intuitiiviset koneet, kun ne on rakennettu, voivat poimia, analysoida ja ymmärtää puheen ja jopa tekstin todellisen merkityksen ja kontekstin.

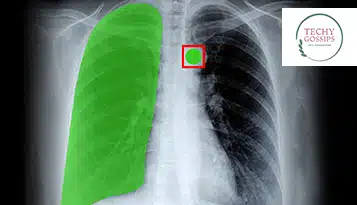
Tässä Medical Image Annotationilla on roolinsa, sillä se välittää tehokkaasti tarvittavaa tietämystä tekoälypohjaisille lääketieteellisille diagnostisille asetuksille, jotka edistävät tarkan tietokonenäön läsnäoloa mallinkehityksen taustalla.

Tekoälyn ei tarvitse olla synkkä aihe keskustellakseen. Tekoäly on täynnä mahdollisuuksia tulla tulevien vuosien mullistavimmaksi työkaluksi, ja se on nopeasti muotoutumassa avustavaksi resurssiksi sen sijaan, että pysyisi kurssilla ylivoimaisena teknologiana.

Oletko tietoinen teknisistä seikoista, jotka liittyvät koneoppimismallien tekemiseen kokonaisvaltaisiksi, intuitiivisiksi ja vaikuttaviksi? Jos ei, sinun on ensin ymmärrettävä, kuinka kukin prosessi on laajalti erotettu kolmeen vaiheeseen, eli hauskaan, toiminnallisuuteen ja hienostuneisuuteen. Kun "Finesse" koskee ML-algoritmien koulutusta täydellisyyteen kehittämällä ensin monimutkaisia ohjelmia asianmukaisilla ohjelmointikielillä, "Fun" -osassa on kyse asiakkaiden tyytyväisyydestä tarjoamalla heille havainnollinen ja älykäs hauska tuote.

Kuvittele, että heräät eräänä kauniina päivänä ja näet kaikki keittiöastiasi markkinoilla mustina, mikä sokaisee sinua näkemään, mitä sisällä on. Ja sitten sokeripalojen löytäminen teetä varten on haaste. Edellyttäen, että voit löytää teen ensin.

Tietojen merkintä on yksinkertaisesti tietojen merkitsemisprosessi, jotta koneet voivat käyttää niitä. Se on erityisen hyödyllinen valvotussa koneoppimisessa (ML), jossa järjestelmä käyttää merkittyjä tietojoukkoja käsitelläkseen, ymmärtääkseen ja oppiakseen syöttömalleja haluttujen tulosten saavuttamiseksi.

Tietojen merkitseminen ei ole niin vaikeaa, ei kukaan organisaatio koskaan sanonut! Mutta huolimatta haasteista matkan varrella, monet eivät ymmärrä käsillä olevien tehtävien vaativuutta. Tietojoukkojen merkitseminen erityisesti tekoäly- ja koneoppimismalleihin soveltuviksi vaatii vuosien kokemusta ja käytännön uskottavuutta. Ja kaiken lisäksi tietojen merkitseminen ei ole yksiulotteinen lähestymistapa, vaan se vaihtelee työstettävän mallin tyypin mukaan.

Tietojen hankinta puheprojekteja varten on yksinkertaisempaa, kun omaksut systemaattisen lähestymistavan. Lue eksklusiivinen viestimme tiedonkeruusta puheprojekteja varten ja saat selvyyttä.

Yksinkertaisesti sanottuna tekstimerkinnöissä on kyse tiettyjen asiakirjojen, digitaalisten tiedostojen ja jopa niihin liittyvän sisällön merkitsemisestä. Kun nämä resurssit on merkitty tai merkitty, niistä tulee ymmärrettäviä, ja koneoppimisalgoritmit voivat käyttää niitä mallien kouluttamiseksi täydellisyyteen.

Tänään olemme valinneet Vatsal Ghiyan haastatteluun. Vatsal Ghiya on sarjayrittäjä, jolla on yli 20 vuoden kokemus terveydenhuollon tekoälyohjelmistoista ja -palveluista. Hän on Shaipin toimitusjohtaja ja perustaja, joka mahdollistaa alustamme, prosessiemme ja henkilöiden tarpeen mukaan skaalauksen yrityksille, joilla on vaativimmat koneoppimis- ja tekoälyhankkeet.

Rahoituspalvelut ovat muuttuneet ajan myötä. Mobiilimaksamisen, henkilökohtaisten pankkiratkaisujen, paremman luottovalvonnan ja muiden taloudellisten mallien kasvu varmistaa entisestään, että rahan sisällyttäminen ei ole sama kuin muutama vuosi sitten. Vuonna 2021 kyse ei ole vain 'Fin'istä tai rahoituksesta, vaan koko 'FinTech'istä, jossa on häiritseviä rahoitustekniikoita, jotka saavat vaikutuksensa muuttamaan asiakaskokemusta, asiaankuuluvien organisaatioiden toimintatapoja tai tarkalleen ottaen koko finanssialan.
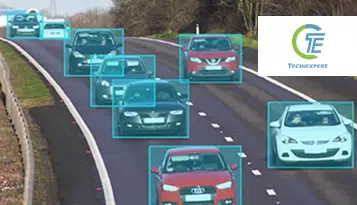
Autoteollisuuden oikea -aikaisesta noususta huolimatta pystysuora jättää paljon mahdollisuuksia lisäparannuksiin. Alkaen liikenneonnettomuuksien vähentämisestä ajoneuvojen valmistuksen ja resurssien käyttöönoton parantamiseen, tekoäly vaikuttaa todennäköisimmältä ratkaisulta saada asiat eteenpäin.

Tekoäly vaikuttaa nykyään enemmän markkinointikieltä. Jokainen tuntemasi yritys, startup-yritys tai yritys mainostaa nyt tuotteitaan ja palvelujaan termillä "AI-powered". Totta tästä huolimatta tekoäly tuntuu varmasti väistämättömältä nykyään. Jos huomaat, lähes kaikki ympärilläsi olevat ovat AI: n voimin. Netflixin suositusmoottoreista ja treffisovellusten algoritmeista joihinkin terveydenhuollon monimutkaisimpiin kokonaisuuksiin, jotka auttavat onkologiassa, tekoäly on kaiken tukipiste.

Koneoppimisella on luultavasti maailman sekaisin määritelmät ja tulkinnat. Muutama vuosi sitten saapunut muotisana sai edelleen monia ihmisiä hämmentymään sen esitystavan ja esitystavan ansiosta.

Tekoäly (AI) on kunnianhimoinen ja erittäin hyödyllinen ihmiskunnan kehityksen kannalta. Erityisesti terveydenhuollon kaltaisessa tilassa tekoäly saa aikaan merkittäviä muutoksia tavoissa, joilla lähestymme sairauksia, niiden hoitoja, potilaiden hoitoa ja potilaiden seurantaa. Unohtamatta tutkimusta ja kehitystä, joka liittyy uusien lääkkeiden kehittämiseen, uudempiin tapoihin löytää huolenaiheita ja taustalla olevia ehtoja ja paljon muuta.

Terveydenhuolto vertikaalina ei koskaan ollut staattinen. Mutta sitten se ei ole koskaan ollut näin dynaamista, koska erilaisten lääketieteellisten näkemysten yhtymäkohta on saanut meidät tuijottamaan elottomasti rakenteellisten tietojen kasoja. Ollakseni rehellinen, jättimäinen tietomäärä ei ole enää edes ongelma. Se on todellisuutta, joka ylitti jopa 2,000 Exabyte -rajan vuoden 2020 loppuun mennessä.

Tekoäly on tekniikka, joka antaa koneille mahdollisuuden jäljitellä ihmisten käyttäytymistä. Kyse on koneiden opettamisesta itsenäiseen oppimiseen ja ajatteluun sekä tulosten käyttämiseen reagoimiseen ja vastaamiseen.

Joka kerta kun GPS -navigointijärjestelmäsi pyytää sinua kiertämään liikennettä, huomaa, että tällainen tarkka analyysi ja tulokset tulevat useiden satojen tuntien harjoittelun jälkeen. Aina kun Google Lens -sovelluksesi tunnistaa esineen tai tuotteen tarkasti, ymmärrä, että sen AI (Artificial Intelligence) -moduuli on käsitellyt tuhansia kuvia tuhansien kuvien jälkeen.

4 Perustietoa tietojen poistamisesta Tunnistaminen: Tietojen luominen tapahtuu 2.5 quintillion tavua päivittäin, ja me internetin käyttäjinä tuotimme lähes 1.7 Mt joka sekunti vuonna 2020.

Nyt kun koko planeetta on verkossa ja yhteydessä, tuotamme yhdessä mittaamattomia määriä dataa. Teollisuus, yritys, markkinasegmentti tai mikä tahansa muu yhteisö näkisi tietoja yhtenä yksikkönä. Silti yksilöiden osalta dataa kutsutaan paremmin digitaaliseksi jalanjäljeksi.

Laadutiedot merkitsevät menestystarinoita, kun taas heikko tietojen laatu tekee hyvän tapaustutkimuksen. Jotkut vaikuttavimmista tapaustutkimuksista tekoälyn toiminnallisuudesta ovat johtuneet laadukkaiden tietojoukkojen puutteesta. Vaikka kaikki yritykset ovat innoissaan ja kunnianhimoisista tekoälyhankkeistaan ja tuotteistaan, innostus ei heijastu tietojen keräämiseen ja koulutukseen. Useampi yritys keskittyy enemmän tuotokseen kuin koulutukseen, mikä viivästyttää markkinointiaikaa, menettää rahoituksen tai jopa vetää ikkunaluukut ikuisuuteen.

Prosessi tuotettujen tietojen merkitsemiseen tai merkitsemiseen, mikä antaa koneoppimisen ja tekoälyn algoritmien mahdollisuuden tunnistaa tehokkaasti kukin tietotyyppi ja päättää, mitä siitä oppia ja mitä sen kanssa tehdä. Mitä tarkemmin määritelty tai merkitty kukin tietojoukko on, sitä paremmin algoritmit pystyvät käsittelemään sen optimoidun tuloksen saavuttamiseksi.
Alexa, onko lähelläni sushi-paikka? Usein kysytään avoimia kysymyksiä virtuaalisille avustajillemme. Tällaisten kysymysten esittäminen muille ihmisille on ymmärrettävää, kun otetaan huomioon, kuinka olemme tottuneet puhumaan ja vuorovaikutuksessa. Ei kuitenkaan ole mitään järkeä, jos kysytään hyvin rento kysymys koneelle, jolla tuskin on käsitys kielestä ja keskustelun monimutkaisuudesta?

Jokaisen yllättävän tapahtuman takana on toiminnassa käsitteitä, kuten tekoäly, koneoppiminen ja mikä tärkeintä, NLP (Natural Language Processing). Yksi viime aikojen suurimmista läpimurroista on NLP, jossa koneet kehittyvät vähitellen ymmärtääkseen, miten ihmiset puhuvat, emoottavat, ymmärtävät, reagoivat, analysoivat ja jopa jäljittelevät ihmisten keskusteluja ja tunteisiin perustuvaa käyttäytymistä. Tämä käsite on ollut erittäin vaikuttava chatbottien, teksti puheeksi -työkalujen, äänentunnistuksen, virtuaalisten avustajien ja muun kehityksessä.

Huolimatta käsitteestä, joka otettiin käyttöön 1950-luvulla, tekoälystä (AI) tuli yleinen nimi vasta pari vuotta sitten. Tekoälyn kehitys on ollut asteittaista, ja se on kestänyt melkein 6 vuosikymmentä tarjota nykyään hulluja ominaisuuksia ja toimintoja. Kaikki tämä on ollut äärimmäisen mahdollista johtuen laitteisto-oheislaitteiden, teknisten infrastruktuurien, liittoutuneiden konseptien, kuten pilvipalvelujen, tietojen tallennus- ja käsittelyjärjestelmien (Big Data and analytics), samanaikaisesta kehityksestä, Internetin levinneisyydestä ja kaupallistamisesta ja muusta. Kaikki yhdessä on johtanut tähän hämmästyttävään teknisen aikajanan vaiheeseen, jossa tekoäly ja koneoppiminen (ML) eivät vain tarjoa innovaatioita, vaan niistä tulee väistämättömiä käsitteitä myös ilman elämää.

Jokainen tekoälyjärjestelmä tarvitsee valtavan määrän laadukkaita tietoja kouluttaakseen ja tuottamaan tarkkoja tuloksia. Nyt tässä lauseessa on kaksi avainsanaa - valtavat määrät ja laatutiedot. Keskustellaan molemmista erikseen.

Kaikki tähän mennessä tehdyt keskustelut tekoälyn käyttöönotosta liike- ja toimintatarkoituksiin ovat olleet vain pinnallisia. Jotkut puhuvat niiden toteuttamisen eduista, kun taas toiset keskustelevat siitä, kuinka tekoälymoduuli voi lisätä tuottavuutta 40%. Mutta tuskin vastaamme todellisiin haasteisiin, jotka liittyvät niiden sisällyttämiseen liiketoiminnallisiin tarkoituksiimme.
On vaikea kuvitella maailmanlaajuisen pandemian torjumista ilman tekniikoita, kuten tekoäly (AI) ja koneoppiminen (ML). Covid-19-tapausten räjähdysmäinen nousu ympäri maailmaa jättää monet terveysinfrastruktuurit halvaantuneiksi. Laitokset, hallitukset ja järjestöt pystyivät kuitenkin taistelemaan edistyneiden tekniikoiden avulla. Tekoälystä ja koneoppimisesta, jota pidettiin kerran ylellisen elämäntavan ja tuottavuuden ylellisyytenä, on lukemattomien sovellustensa ansiosta tullut hengenpelastavia aineita Covidin torjunnassa.

Kipu koetaan voimakkaammin tiettyjen ihmisryhmien keskuudessa. Tutkimukset ovat osoittaneet, että vähemmistöryhmistä ja heikommassa asemassa olevista ryhmistä kärsivät ihmiset kokevat enemmän fyysistä kipua kuin väestö stressin, yleisen terveyden ja muiden tekijöiden vuoksi.

Ennen kuin aiot edes hankkia tietoja, yksi tärkeimmistä näkökohdista määritettäessä, kuinka paljon sinun pitäisi käyttää tekoälyn harjoitustietoihin. Tässä artikkelissa annamme sinulle oivalluksia kehittää tehokas budjetti tekoälyn harjoitustiedoille.

Shaip on online-foorumi, joka keskittyy terveydenhuollon tekoälyn tietoratkaisuihin ja tarjoaa lisensoituja terveystietoja, jotka on suunniteltu auttamaan tekoälyn mallien rakentamisessa. Se tarjoaa tekstipohjaisia potilastietoja ja väitetietoja, ääntä, kuten lääkärin nauhoituksia tai potilaan / lääkärin keskusteluja, sekä kuvia ja videoita röntgensäteiden, TT-kuvien ja MRI-tulosten muodossa.

Data on yksi tärkeimmistä tekijöistä tekoälyn algoritmin kehittämisessä. Muista, että se, että tietoja tuotetaan nopeammin kuin koskaan ennen, ei tarkoita sitä, että oikeat tiedot on helppo saada. Huonolaatuinen, puolueellinen tai väärin merkitty tieto voi (parhaimmillaan) lisätä toisen vaiheen. Nämä ylimääräiset vaiheet hidastavat sinua, koska datatieteen ja kehitystiimien on työskenneltävä niiden läpi matkalla toimivaan sovellukseen.

Paljon on tehty tekoälyn mahdollisuudesta muuttaa terveydenhuollon alaa, ja hyvästä syystä. Kehittyneitä tekoälyalustoja tukevat tiedot, ja terveydenhuollon organisaatioilla on sitä runsaasti. Joten miksi teollisuus on jäljessä muista tekoälyn käyttöönotossa? Se on monipuolinen kysymys, johon sisältyy monia mahdollisia vastauksia. Ne kaikki korostavat kuitenkin epäilemättä erityisesti yhden esteen: suuria määriä strukturoimattomia tietoja.

Se, mikä vaikuttaa yksinkertaiselta, on kuitenkin tylsää kehittää ja ottaa käyttöön kuten mitä tahansa muuta monimutkaista tekoälyjärjestelmää. Ennen kuin laitteesi tunnisti kaapattavan kuvan ja Machine Learning (ML) -moduulit pystyivät käsittelemään sen, datan merkitsijä tai heidän tiiminsä olisi viettänyt tuhansia tunteja tietojen merkinnöillä, jotta koneet ymmärtäisivät ne.

Shaipin toimitusjohtaja ja perustaja Vatsal Ghiya tutkii tässä erityisominaisuudessa kolmea tekijää, joiden hän uskoo antavan dataan perustuvan tekoälyn saavuttaa täyden potentiaalinsa tulevaisuudessa: innovatiivisten algoritmien rakentamiseen tarvittavat kyvyt ja resurssit. valtava tietomäärä näiden algoritmien tarkkaan kouluttamiseen ja runsaasti prosessointitehoa näiden tietojen tehokkaaseen louhintaan. Vatsal on sarjayrittäjä, jolla on yli 20 vuoden kokemus terveydenhuollon tekoälyohjelmistoista ja -palveluista. Shaip mahdollistaa alustan, prosessien ja ihmisten skaalautumisen tarpeen mukaan yrityksille, joilla on vaativimmat koneoppimis- ja tekoälyaloitteet.

Tekoälyjärjestelmien (AI) prosessit ovat evoluution mukaisia. Toisin kuin muut markkinoilla olevat tuotteet, palvelut tai järjestelmät, tekoälymallit eivät tarjoa välittömän käytön tapauksia tai heti 100% tarkkoja tuloksia. Tulokset kehittyvät, kun asiaankuuluvia ja laatutietoja käsitellään enemmän. Se on kuin kuinka vauva oppii puhumaan tai kuinka muusikko aloittaa oppimalla viisi ensimmäistä suurta sointua ja rakentaa sitten niitä. Saavutuksia ei avata yön yli, mutta harjoittelu tapahtuu jatkuvasti huippuosaamista varten.

Aina kun puhumme tekoälystä (AI) ja koneoppimisesta (ML), kuvittelemme heti voimakkaat teknologiayritykset, kätevät ja futuristiset ratkaisut, hienot itse ajavat autot ja pohjimmiltaan kaiken, mikä on esteettisesti, luovasti ja älyllisesti miellyttävää. Mikä tuskin heijastuu ihmisille, on todellinen maailma kaikkien tekoälyn tarjoamien mukavuuksien ja elämäntapakokemusten takana.

Eksklusiivinen haastattelu, jossa yrityspäällikkö Utsav - Shaip on vuorovaikutuksessa My Startupin päätoimittaja Sunilin kanssa kertoakseen hänelle, kuinka Shaip parantaa ihmisten elämää ratkaisemalla tulevaisuuden ongelmat keskustelu- ja terveydenhuollon tekoälyn tarjouksilla. Hän kertoo edelleen, kuinka tekoäly, ML on asetettu mullistamaan liiketoimintatapamme ja kuinka Shaip osallistuu seuraavan sukupolven teknologioiden kehittämiseen.
Tekoäly (AI) parantaa elintapojamme parempien elokuvasuositusten, ravintola-ehdotusten, konfliktien ratkaisemisen chat-robottien avulla ja paljon muuta. Tekoälyn voimaa, potentiaalia ja ominaisuuksia hyödynnetään yhä enemmän kaikilla teollisuudenaloilla ja alueilla, joita kukaan ei todennäköisesti ajatellut. Itse asiassa tekoälyä tutkitaan ja pannaan täytäntöön esimerkiksi terveydenhuollon, vähittäiskaupan, pankkitoiminnan, rikosoikeuden, valvonnan, palkkaamisen, palkkaerojen korjaamisen ja muilla aloilla.

Olemme kaikki nähneet, mitä tapahtuu, kun tekoälyn kehitys menee pieleen. Harkitse Amazonin yritystä luoda tekoälyn rekrytointijärjestelmä, joka oli loistava tapa skannata ansioluettelot ja tunnistaa pätevimmät ehdokkaat - edellyttäen että nämä ehdokkaat olivat miehiä.

Terveydenhuoltoala testattiin viime vuonna pandemian takia, ja paljon innovaatioita loi läpi - uusista lääkkeistä ja lääkinnällisistä laitteista toimitusketjun läpimurtoihin ja parempiin yhteistyöprosesseihin. Yritysjohtajat kaikilta toimialoilta löysivät uusia tapoja nopeuttaa kasvua yleisen edun tukemiseksi ja kriittisten tulojen tuottamiseksi.

Olemme nähneet heitä elokuvissa, olemme lukeneet niistä kirjoista ja olemme kokeneet niitä tosielämässä. Niin scifi kuin se saattaa tuntua, Meidän on kohdattava tosiasiat - kasvojentunnistus on täällä pysyä. Tekniikka kehittyy dynaamisella nopeudella, ja eri toimialoilla esiintyvien monipuolisten käyttötapausten myötä kasvojen tunnistamisen laaja kehitys näyttää yksinkertaisesti väistämättömältä ja loputtomalta.

Monikieliset chat-robotit muuttavat liike-elämää. Chatbotit ovat edenneet pitkälle niiden alkuvaiheista lähtien, missä he antaisivat yksinkertaisia yhden sanan vastauksia. Chatbot voi nyt keskustella sujuvasti kymmenillä kielillä, jolloin yritykset voivat laajentua laajemmille globaaleille markkinoille.

Terveydenhuoltoa pidetään usein teknologisen innovaation kärjessä olevana toimialana. Se on totta monin tavoin, mutta terveydenhuollon tilaa säätelee myös laaja lainsäädäntö, kuten GDPR ja HIPAA, sekä monet muut paikalliset ohjeet ja rajoitukset.

Vuoden 2018 raportti paljasti, että tuotimme lähes 2.5 kvintillionia tavua tietoja joka päivä. Toisin kuin yleisesti uskotaan, kaikkia luomiamme tietoja ei voida käsitellä oivallusten saamiseksi.

Tekoäly on älykkäämpi päivä päivältä. Nykyään tehokkaat koneoppimisalgoritmit ovat normaalien yritysten ulottuvilla, ja algoritmit, jotka vaativat prosessointitehoa, joka olisi kerran varattu massiivisille keskusyksiköille, voidaan nyt ottaa käyttöön kohtuuhintaisissa pilvipalvelimissa.