




Terveydenhuollon voimaannuttaminen generatiivisella tekoälyllä: Mullistava diagnoosi ja hoito
Viime vuosina tekoäly (AI) on edistynyt merkittävästi useilla toimialoilla, eikä terveydenhuolto ole poikkeus. Generatiivinen tekoäly, tekoälyyn keskittyvä osajoukko
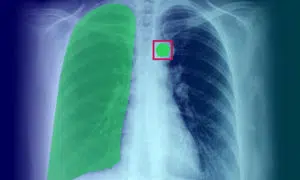
Lääketieteellisen kuvan huomautus: määritelmä, sovellus, käyttötapaukset ja tyypit
Lääketieteellisten kuvien merkinnöillä on tärkeä rooli koneoppimisalgoritmeille ja tekoälymalleille tarvittavan harjoitusdatan tarjoamisessa. Tämä prosessi on välttämätön

Etiikka ja harha: Ihmisen ja tekoälyn yhteistyön haasteisiin siirtyminen mallin arvioinnissa
Pyrkiessään hyödyntämään tekoälyn (AI) muuntavaa voimaa teknologiayhteisö kohtaa kriittisen haasteen: varmistaa eettisen eheyden ja minimoida puolueellisuuden.

Ihmisen kosketus: tekoälyn luovuuden parantaminen subjektiivisen arvioinnin avulla
Nopeasti kehittyvässä tekoälyn maailmassa luovuuden etsintä ei ole enää vain ihmisen yritystä. Tämän päivän tekoälytekniikat murtuvat

Haun osuvuuden maksimointi tietojen merkitsemisellä: vinkkejä ja parhaita käytäntöjä
Nykyään käyttäjät ovat uppoamassa valtaviin tietomääriin, mikä tekee heidän tarvitsemansa tiedon löytämisestä monimutkaista. Haun relevanssi mittaa tiedon tarkkuutta

Kuilun kurominen: Ihmisen intuition integrointi tekoälymallin arviointiin
Johdanto Aikana, jolloin tekoäly (AI) muokkaa elämämme kaikkia puolia, ihmisen intuition integrointi tekoälymallien arviointiin tulee esiin

Parhaat avoimen lähdekoodin terveydenhuollon tietojoukot koneoppimisprojekteihin
Globaali terveydenhuoltojärjestelmä tuottaa päivittäin valtavia määriä lääketieteellistä dataa, jota voidaan hyödyntää koneoppimissovelluksissa.

Tietosuojassa liikkuminen tekoälyssä: vaatimustenmukaisuuden ja innovaation strategiat
Johdanto Tekoälyn (AI) nopeasti kehittyvässä ympäristössä OpenAI:n kaltaiset yritykset kohtaavat merkittäviä haasteita tasapainottaa kyltymätön datan tarve tiukkojen tietojen kanssa.
Tietojen tulevaisuus älykkäällä merkintunnistuksella (ICR)
Käsinkirjoitetuilla muistiinpanoilla on erityinen viehätys jopa digitaalisessa maailmassamme. Älykäs merkintunnistus (ICR) auttaa kuromaan umpeen analogisen ja digitaalisen kuilun muuntaen käsinkirjoitetun tekstin

NLP:n vaikutus terveydenhuollon diagnostiikkaan
Natural Language Processing (NLP) muuttaa tapaamme olla vuorovaikutuksessa teknologian kanssa. Se käsittelee ihmisten kieltä vapauttaakseen valtavan tietopotentiaalin. Tekniikassa on sama potentiaali

Oikean puheentunnistustietojoukon valitseminen tekoälymallillesi
Kuvittele, että olet vuorovaikutuksessa Sirin tai Alexan kanssa. Heidän kykynsä ymmärtää puheemme on kiehtovaa. Tämä ominaisuus johtuu heidän koulutuksessaan käytetyistä tietojoukoista. Nämä

Terveydenhuollon tietojoukot: Boon for Healthcare AI
Tekoäly, jota aiemmin esiintyi enimmäkseen tieteiskirjallisuudesta, on nyt todellisuutta, joka ruokkii eri toimialojen kasvua. Next Move Strategy Consulting

Oppimisen vahvistaminen ihmispalautteen avulla: määritelmä ja vaiheet
Vahvistusoppiminen (RL) on eräänlainen koneoppiminen. Tässä lähestymistavassa algoritmit oppivat tekemään päätöksiä yrityksen ja erehdyksen kautta, aivan kuten ihmiset tekevät.

AI-hallusinaatioiden syyt (ja tekniikat niiden vähentämiseksi)
AI-hallusinaatiot viittaavat tapauksiin, joissa tekoälymallit, erityisesti suuret kielimallit (LLM) tuottavat tietoja, jotka vaikuttavat todelta, mutta ovat virheellisiä tai eivät liity

Mikä on kliininen validointi? Opas parhaisiin käytäntöihin ja prosesseihin
Ajattele skenaariota, jossa kehitetään uusi diagnostiikkatyökalu. Lääkärit ovat innoissaan sen mahdollisuuksista. Kuitenkin ennen sen integroimista rutiinihoitoon he

Eettisen tekoälyn merkitys / oikeudenmukainen tekoäly ja vältettävät harhatyypit
Tekoälyn (AI) nousevalla alalla keskittyminen eettisiin näkökohtiin ja oikeudenmukaisuuteen on enemmän kuin moraalinen pakko – se on perustavanlaatuinen välttämättömyys

Tekoälyn potilastietojen yhteenveto: määritelmä, haasteet ja parhaat käytännöt
Terveydenhuollon potilastietojen kasvusta on tullut sekä haaste että mahdollisuus. Kuvittele maailma, jossa jokainen yksityiskohta a

Kliinisen tiedon abstraktio: määritelmä, prosessi ja paljon muuta
Sairaalat ja klinikat kohtaavat tuhansia potilaita vuosittain. Tämä vaatii valtavan määrän omistautuneita lääkäreitä ja sairaanhoitajia. He työskentelevät väsymättä tarjotakseen hoitoa

Synteettinen data terveydenhuollossa: määritelmä, hyödyt ja haasteet
Kuvittele skenaario, jossa tutkijat kehittävät uutta lääkettä. He tarvitsevat laajoja potilastietoja testausta varten, mutta yksityisyyteen ja yksityisyyteen liittyvät huolenaiheet ovat merkittäviä

HIPAA:n asiantuntijapäätös henkilöllisyyden poistamiseksi
Health Insurance Portability and Accountability Act (HIPAA) asettaa standardin potilastietojen suojaamiselle terveydenhuollossa. Olennainen näkökohta tässä on suojatun tunnistamisen poistaminen

Uraauurtava onkologiatutkimus NLP:n kanssa: Shaipin läpimurto
Lataa tapaustutkimus Syövän voittamisessa data on yhtä tärkeää kuin päättäväisyys. Olemme Shaipilla ylpeitä siitä, että teimme suuren harppauksen
Luonnollisen kielen käsittelyn (NLP) voima radiologiassa: diagnosoinnin ja tehokkuuden parantaminen
Radiologialla on keskeinen rooli terveydenhuollossa. Se käyttää kuvantamistekniikoita, kuten CT-skannauksia, röntgensäteitä ja MRI:tä erilaisten sairauksien diagnosointiin ja hoitoon. Luonnollinen kieli

Luonnollisen kielenkäsittelyn (NLP) rooli onkologiassa
Syöpä on merkittävä terveyshaaste maailmanlaajuisesti. Se tapahtuu, kun solut kasvavat ja leviävät hallitsemattomasti. Se on toiseksi yleisin kuolinsyy

Kaikki mitä sinun tarvitsee tietää vahvistamisesta Ihmisten palautteesta oppiminen
Vuonna 2023 AI-työkalujen, kuten ChatGPT:n, käyttöönotto lisääntyi valtavasti. Tämä nousu aloitti vilkkaan keskustelun ja ihmiset keskustelevat tekoälyn eduista,

Tekoälyn voima autoteollisuudessa
Mitä tulee tekoälyn integroimiseen autoihin, maailma on merkittävässä tienhaarassa. Kuvittele ajaessasi vilkkaalla tiellä tekoälyn kanssa ja hallitsemaan omaasi

Tekstistä puheeksi -tekniikan edut eri toimialoilla
Text-to-speech (TTS) -tekniikka on innovatiivinen ratkaisu, joka muuntaa kirjoitetun tekstin puhutuksi. Siitä on tullut pelin muuttaja useilla toimialoilla ja se on mullistanut

Tietojen merkinnät A - Z
Aloittelijan opas tietomerkintöihin: Vinkkejä ja parhaita käytäntöjä Ultimate Buyers Guide 2024 Hakemistotaulukko Johdanto Mitä koneoppiminen on? Mikä on

Tietojen tunnistamisen poistoopas: kaikki mitä aloittelijan tulee tietää (vuonna 2024)
Digitaalisen muutoksen aikakaudella terveydenhuollon organisaatiot siirtävät nopeasti toimintaansa digitaalisille alustoille. Vaikka tämä tuo tehokkuutta ja virtaviivaistaa prosesseja, se myös

Generatiivinen tekoäly terveydenhuollossa: sovellukset, edut, haasteet ja tulevaisuuden trendit
Terveydenhuolto on aina ollut ala, jolla innovaatioita arvostetaan ja se on elintärkeää ihmishenkien pelastamiselle. Teknologisesta kehityksestä huolimatta terveydenhuoltoalalla on edelleen edessään pitkiä haasteita.

Ero vastuullisen tekoälyn ja eettisen tekoälyn välillä
Nopeasti kasvavien maailmanlaajuisten tekoälymarkkinoiden odotetaan nousevan 1847 miljardiin dollariin vuonna 2030. Tekoälyn ollessa keskeinen osa elämässämme, tiedämme millaisia



















Terveydenhuollon voimaannuttaminen generatiivisella tekoälyllä: Mullistava diagnoosi ja hoito
Viime vuosina tekoäly (AI) on edistynyt merkittävästi useilla toimialoilla, eikä terveydenhuolto ole poikkeus. Generatiivinen tekoäly, tekoälyyn keskittyvä osajoukko
Lääketieteellisen kuvan huomautus: määritelmä, sovellus, käyttötapaukset ja tyypit
Lääketieteellisten kuvien merkinnöillä on tärkeä rooli koneoppimisalgoritmeille ja tekoälymalleille tarvittavan harjoitusdatan tarjoamisessa. Tämä prosessi on välttämätön
Etiikka ja harha: Ihmisen ja tekoälyn yhteistyön haasteisiin siirtyminen mallin arvioinnissa
Pyrkiessään hyödyntämään tekoälyn (AI) muuntavaa voimaa teknologiayhteisö kohtaa kriittisen haasteen: varmistaa eettisen eheyden ja minimoida puolueellisuuden.
Ihmisen kosketus: tekoälyn luovuuden parantaminen subjektiivisen arvioinnin avulla
Nopeasti kehittyvässä tekoälyn maailmassa luovuuden etsintä ei ole enää vain ihmisen yritystä. Tämän päivän tekoälytekniikat murtuvat
Haun osuvuuden maksimointi tietojen merkitsemisellä: vinkkejä ja parhaita käytäntöjä
Nykyään käyttäjät ovat uppoamassa valtaviin tietomääriin, mikä tekee heidän tarvitsemansa tiedon löytämisestä monimutkaista. Haun relevanssi mittaa tiedon tarkkuutta
Kuilun kurominen: Ihmisen intuition integrointi tekoälymallin arviointiin
Johdanto Aikana, jolloin tekoäly (AI) muokkaa elämämme kaikkia puolia, ihmisen intuition integrointi tekoälymallien arviointiin tulee esiin
Parhaat avoimen lähdekoodin terveydenhuollon tietojoukot koneoppimisprojekteihin
Globaali terveydenhuoltojärjestelmä tuottaa päivittäin valtavia määriä lääketieteellistä dataa, jota voidaan hyödyntää koneoppimissovelluksissa.
Tietosuojassa liikkuminen tekoälyssä: vaatimustenmukaisuuden ja innovaation strategiat
Johdanto Tekoälyn (AI) nopeasti kehittyvässä ympäristössä OpenAI:n kaltaiset yritykset kohtaavat merkittäviä haasteita tasapainottaa kyltymätön datan tarve tiukkojen tietojen kanssa.
Tietojen tulevaisuus älykkäällä merkintunnistuksella (ICR)
Käsinkirjoitetuilla muistiinpanoilla on erityinen viehätys jopa digitaalisessa maailmassamme. Älykäs merkintunnistus (ICR) auttaa kuromaan umpeen analogisen ja digitaalisen kuilun muuntaen käsinkirjoitetun tekstin
NLP:n vaikutus terveydenhuollon diagnostiikkaan
Natural Language Processing (NLP) muuttaa tapaamme olla vuorovaikutuksessa teknologian kanssa. Se käsittelee ihmisten kieltä vapauttaakseen valtavan tietopotentiaalin. Tekniikassa on sama potentiaali
Oikean puheentunnistustietojoukon valitseminen tekoälymallillesi
Kuvittele, että olet vuorovaikutuksessa Sirin tai Alexan kanssa. Heidän kykynsä ymmärtää puheemme on kiehtovaa. Tämä ominaisuus johtuu heidän koulutuksessaan käytetyistä tietojoukoista. Nämä
Terveydenhuollon tietojoukot: Boon for Healthcare AI
Tekoäly, jota aiemmin esiintyi enimmäkseen tieteiskirjallisuudesta, on nyt todellisuutta, joka ruokkii eri toimialojen kasvua. Next Move Strategy Consulting
Oppimisen vahvistaminen ihmispalautteen avulla: määritelmä ja vaiheet
Vahvistusoppiminen (RL) on eräänlainen koneoppiminen. Tässä lähestymistavassa algoritmit oppivat tekemään päätöksiä yrityksen ja erehdyksen kautta, aivan kuten ihmiset tekevät.
AI-hallusinaatioiden syyt (ja tekniikat niiden vähentämiseksi)
AI-hallusinaatiot viittaavat tapauksiin, joissa tekoälymallit, erityisesti suuret kielimallit (LLM) tuottavat tietoja, jotka vaikuttavat todelta, mutta ovat virheellisiä tai eivät liity
Mikä on kliininen validointi? Opas parhaisiin käytäntöihin ja prosesseihin
Ajattele skenaariota, jossa kehitetään uusi diagnostiikkatyökalu. Lääkärit ovat innoissaan sen mahdollisuuksista. Kuitenkin ennen sen integroimista rutiinihoitoon he
Eettisen tekoälyn merkitys / oikeudenmukainen tekoäly ja vältettävät harhatyypit
Tekoälyn (AI) nousevalla alalla keskittyminen eettisiin näkökohtiin ja oikeudenmukaisuuteen on enemmän kuin moraalinen pakko – se on perustavanlaatuinen välttämättömyys
Tekoälyn potilastietojen yhteenveto: määritelmä, haasteet ja parhaat käytännöt
Terveydenhuollon potilastietojen kasvusta on tullut sekä haaste että mahdollisuus. Kuvittele maailma, jossa jokainen yksityiskohta a
Kliinisen tiedon abstraktio: määritelmä, prosessi ja paljon muuta
Sairaalat ja klinikat kohtaavat tuhansia potilaita vuosittain. Tämä vaatii valtavan määrän omistautuneita lääkäreitä ja sairaanhoitajia. He työskentelevät väsymättä tarjotakseen hoitoa
Synteettinen data terveydenhuollossa: määritelmä, hyödyt ja haasteet
Kuvittele skenaario, jossa tutkijat kehittävät uutta lääkettä. He tarvitsevat laajoja potilastietoja testausta varten, mutta yksityisyyteen ja yksityisyyteen liittyvät huolenaiheet ovat merkittäviä
HIPAA:n asiantuntijapäätös henkilöllisyyden poistamiseksi
Health Insurance Portability and Accountability Act (HIPAA) asettaa standardin potilastietojen suojaamiselle terveydenhuollossa. Olennainen näkökohta tässä on suojatun tunnistamisen poistaminen
Uraauurtava onkologiatutkimus NLP:n kanssa: Shaipin läpimurto
Lataa tapaustutkimus Syövän voittamisessa data on yhtä tärkeää kuin päättäväisyys. Olemme Shaipilla ylpeitä siitä, että teimme suuren harppauksen
Luonnollisen kielen käsittelyn (NLP) voima radiologiassa: diagnosoinnin ja tehokkuuden parantaminen
Radiologialla on keskeinen rooli terveydenhuollossa. Se käyttää kuvantamistekniikoita, kuten CT-skannauksia, röntgensäteitä ja MRI:tä erilaisten sairauksien diagnosointiin ja hoitoon. Luonnollinen kieli
Luonnollisen kielenkäsittelyn (NLP) rooli onkologiassa
Syöpä on merkittävä terveyshaaste maailmanlaajuisesti. Se tapahtuu, kun solut kasvavat ja leviävät hallitsemattomasti. Se on toiseksi yleisin kuolinsyy
Kaikki mitä sinun tarvitsee tietää vahvistamisesta Ihmisten palautteesta oppiminen
Vuonna 2023 AI-työkalujen, kuten ChatGPT:n, käyttöönotto lisääntyi valtavasti. Tämä nousu aloitti vilkkaan keskustelun ja ihmiset keskustelevat tekoälyn eduista,
Tekoälyn voima autoteollisuudessa
Mitä tulee tekoälyn integroimiseen autoihin, maailma on merkittävässä tienhaarassa. Kuvittele ajaessasi vilkkaalla tiellä tekoälyn kanssa ja hallitsemaan omaasi
Tekstistä puheeksi -tekniikan edut eri toimialoilla
Text-to-speech (TTS) -tekniikka on innovatiivinen ratkaisu, joka muuntaa kirjoitetun tekstin puhutuksi. Siitä on tullut pelin muuttaja useilla toimialoilla ja se on mullistanut
Tietojen merkinnät A - Z
Aloittelijan opas tietomerkintöihin: Vinkkejä ja parhaita käytäntöjä Ultimate Buyers Guide 2024 Hakemistotaulukko Johdanto Mitä koneoppiminen on? Mikä on
Tietojen tunnistamisen poistoopas: kaikki mitä aloittelijan tulee tietää (vuonna 2024)
Digitaalisen muutoksen aikakaudella terveydenhuollon organisaatiot siirtävät nopeasti toimintaansa digitaalisille alustoille. Vaikka tämä tuo tehokkuutta ja virtaviivaistaa prosesseja, se myös
Generatiivinen tekoäly terveydenhuollossa: sovellukset, edut, haasteet ja tulevaisuuden trendit
Terveydenhuolto on aina ollut ala, jolla innovaatioita arvostetaan ja se on elintärkeää ihmishenkien pelastamiselle. Teknologisesta kehityksestä huolimatta terveydenhuoltoalalla on edelleen edessään pitkiä haasteita.
Ero vastuullisen tekoälyn ja eettisen tekoälyn välillä
Nopeasti kasvavien maailmanlaajuisten tekoälymarkkinoiden odotetaan nousevan 1847 miljardiin dollariin vuonna 2030. Tekoälyn ollessa keskeinen osa elämässämme, tiedämme millaisia

Mikä on NLP? Miten se toimii, edut, haasteet, esimerkit
Lataa infografiikka Mikä on NLP? Natural Language Processing (NLP) on tekoälyn (AI) alakenttä. Sen avulla robotit voivat analysoida ja ymmärtää ihmisten kieltä,

OCR – määritelmä, edut, haasteet ja käyttötapaukset [Infographic]
OCR on tekniikka, jonka avulla koneet voivat lukea painettua tekstiä ja kuvia. Sitä käytetään usein yrityssovelluksissa, kuten asiakirjojen digitoinnissa säilytystä tai käsittelyä varten, ja kuluttajasovelluksissa, kuten kulukorvauskuitin skannaamisessa.

Keskustelutaidon tila 2022
The State of Conversational AI 2022 Mikä on Conversational AI? Ohjelmallinen ja älykäs tapa tarjota keskustelukokemus tomimic keskusteluja todellisten ihmisten kanssa, digitaalisen ja telekommunikaation kautta

Mitä tiedonkeruu on? Kaikki aloittelijan tarvitsee tietää
Älykkäitä #AI/ #ML-malleja on kaikkialla, olipa se sitten ennakoivia terveydenhuoltomalleja, ennakoivaa diagnoosia,

Mikä on tietojen merkintä? Kaikki aloittelijan on tiedettävä
Lataa Infographics Älykkäät tekoälymallit on koulutettava laajasti, jotta ne pystyvät tunnistamaan kuvioita, esineitä ja lopulta tekemään luotettavia päätöksiä. Koulutetut kuitenkin