esittely
 Tekoälyssä on kyse koneiden käytöstä ihmisten elämän ja elämäntavan kohottamiseksi tekemällä heidän arkielämästään mielenkiintoisia ja tarpeettomia tehtäviä yksinkertaisia. Tekoälyn ei koskaan ole tarkoitus olla hallitseva voima, vaan täydentävä voima, joka toimii yhdessä ihmisten kanssa ratkaistakseen epäuskottavia asioita ja tasoittaakseen tietä kollektiiviselle evoluutiolle.
Tekoälyssä on kyse koneiden käytöstä ihmisten elämän ja elämäntavan kohottamiseksi tekemällä heidän arkielämästään mielenkiintoisia ja tarpeettomia tehtäviä yksinkertaisia. Tekoälyn ei koskaan ole tarkoitus olla hallitseva voima, vaan täydentävä voima, joka toimii yhdessä ihmisten kanssa ratkaistakseen epäuskottavia asioita ja tasoittaakseen tietä kollektiiviselle evoluutiolle.
Tällä hetkellä kuljemme oikealla tiellä, sillä AI:n avulla on tapahtunut merkittäviä läpimurtoja eri toimialoilla. Jos ottaa esimerkiksi terveydenhuollon, tekoälyjärjestelmät ja koneoppimismallit auttavat asiantuntijoita ymmärtämään syöpää paremmin ja keksimään siihen hoitoja. Neurologisia häiriöitä ja huolenaiheita, kuten PTSD, hoidetaan tekoälyn avulla. Rokotteita kehitetään nopeasti tekoälypohjaisten kliinisten kokeiden ja simulaatioiden ansiosta.
Ei vain terveydenhuolto, vaan jokainen toimiala tai segmentti, johon tekoäly koskettaa, mullistaa. Autonomiset ajoneuvot, älykkäät lähikaupat, puettavat laitteet, kuten FitBit, ja jopa älypuhelinkameramme pystyvät tallentamaan parempia kuvia kasvoistamme tekoälyn avulla.
Tekoälyavaruudessa tapahtuvien innovaatioiden ansiosta yritykset hakeutuvat taajuuksiin erilaisilla käyttötapauksilla ja ratkaisuilla. Tästä johtuen maailmanlaajuisten tekoälymarkkinoiden odotetaan saavuttavan noin 267 miljardin dollarin markkina-arvon vuoden 2027 loppuun mennessä. Lisäksi noin 37 % alan yrityksistä on jo toteuttamassa tekoälyratkaisuja prosesseihinsa ja tuotteisiinsa.
Mielenkiintoisempaa on, että lähes 77 % nykyisin käyttämistämme tuotteista ja palveluista on tekoälyn tuottamia. Kun teknologiakonsepti kasvaa merkittävästi eri toimialoilla, kuinka yritykset onnistuvat tekemään mahdottomia tekoälyn avulla?

 Kuinka niinkin yksinkertaiset laitteet kuin kello ennustavat tarkasti ihmisten sydänkohtauksia? Kuinka on mahdollista, että autot ja autot, jotka ovat aina vaatineet kuljettajaa, ajavat yhtäkkiä vähemmän kuljettajaa teillä?
Kuinka niinkin yksinkertaiset laitteet kuin kello ennustavat tarkasti ihmisten sydänkohtauksia? Kuinka on mahdollista, että autot ja autot, jotka ovat aina vaatineet kuljettajaa, ajavat yhtäkkiä vähemmän kuljettajaa teillä?
Kuinka chatbotit saavat meidät uskomaan, että puhumme toisen ihmisen kanssa toisella puolella?
Jos tarkkailet vastausta jokaiseen kysymykseen, se tiivistyy vain yhteen elementtiin - DATA:seen. Data on kaikkien tekoälykohtaisten toimintojen ja prosessien keskiössä. Se on dataa, joka auttaa koneita ymmärtämään käsitteitä, käsittelemään syötteitä ja tuottamaan tarkkoja tuloksia.
Kaikki olemassa olevat tärkeimmät tekoälyratkaisut ovat kaikki tuotteita, jotka ovat tärkeitä prosessissa, jota kutsumme tiedonkeruuksi tai tiedonkeruuksi tai tekoälyn koulutusdataksi.
Tämän kattavan oppaan tarkoituksena on auttaa sinua ymmärtämään, mikä se on ja miksi se on tärkeää.
Mitä on AI-tiedonkeruu?
Koneilla ei ole omaa mieltään. Tämän abstraktin käsitteen puuttuminen tekee niistä vailla mielipiteitä, tosiasioita ja kykyjä, kuten päättelyä, kognitiota ja muuta. Ne ovat vain liikkumattomia laatikoita tai laitteita, jotka vievät tilaa. Tarvitset algoritmeja ja ennen kaikkea dataa muuttaaksesi ne tehokkaiksi tietovälineiksi.
 Kehitetyt algoritmit tarvitsevat jotain työstettävää ja prosessoitavaa, ja se on dataa, joka on relevanttia, kontekstuaalista ja tuoretta. Tällaisten tietojen keräämistä koneita varten niiden aiottuja tarkoituksia varten kutsutaan tekoälyn tiedonkeruuksi.
Kehitetyt algoritmit tarvitsevat jotain työstettävää ja prosessoitavaa, ja se on dataa, joka on relevanttia, kontekstuaalista ja tuoretta. Tällaisten tietojen keräämistä koneita varten niiden aiottuja tarkoituksia varten kutsutaan tekoälyn tiedonkeruuksi.
Jokainen tekoälyä tukeva tuote tai ratkaisu, jota käytämme nykyään, ja niiden tarjoamat tulokset ovat peräisin vuosien harjoittelusta, kehityksestä ja optimoinnista. Navigointireittejä tarjoavista laitteista monimutkaisiin järjestelmiin, jotka ennustavat laitteiden vikoja päiviä etukäteen, jokainen kokonaisuus on käynyt läpi vuosien tekoälykoulutuksen voidakseen tuottaa tarkkoja tuloksia.
AI-tietojen kerääminen on AI-kehitysprosessin alustava vaihe, joka määrittää alusta alkaen kuinka tehokas tekoälyjärjestelmä olisi. Se on prosessi, jossa hankitaan merkityksellisiä tietojoukkoja lukemattomista lähteistä, mikä auttaa tekoälymalleja käsittelemään yksityiskohtia paremmin ja tuottamaan merkityksellisiä tuloksia.




Kuinka kerätä dataa koneoppimista varten?
 Täällä asiat alkavat mennä hieman hankalaksi. Alusta alkaen näytti siltä, että sinulla on mielessäsi ratkaisu todelliseen ongelmaan, tiedät, että tekoäly olisi ihanteellinen tapa ratkaista se ja olet kehittänyt mallisi. Mutta nyt olet ratkaisevassa vaiheessa, jossa sinun on aloitettava tekoälykoulutuksesi. Tarvitset mukanasi runsaasti tekoälyharjoitteludataa, jotta mallisi oppivat käsitteitä ja tuottavat tuloksia. Tarvitset myös validointitietoja tulosten testaamiseen ja algoritmien optimointiin.
Täällä asiat alkavat mennä hieman hankalaksi. Alusta alkaen näytti siltä, että sinulla on mielessäsi ratkaisu todelliseen ongelmaan, tiedät, että tekoäly olisi ihanteellinen tapa ratkaista se ja olet kehittänyt mallisi. Mutta nyt olet ratkaisevassa vaiheessa, jossa sinun on aloitettava tekoälykoulutuksesi. Tarvitset mukanasi runsaasti tekoälyharjoitteludataa, jotta mallisi oppivat käsitteitä ja tuottavat tuloksia. Tarvitset myös validointitietoja tulosten testaamiseen ja algoritmien optimointiin.
Joten miten hankit tietosi? Mitä tietoja tarvitset ja kuinka paljon niitä? Mistä useista lähteistä tarvittavat tiedot voidaan hakea?
Yritykset arvioivat ML-malliensa markkinaraon ja tarkoituksen sekä kartoittavat mahdollisia tapoja hankkia relevantteja tietojoukkoja. Tarvittavan tietotyypin määrittäminen ratkaisee suuren osan tiedonhankintaan liittyvistä huolenaiheistasi. Jotta saat paremman käsityksen, tiedonkeruussa on erilaisia kanavia, tapoja, lähteitä tai välineitä:
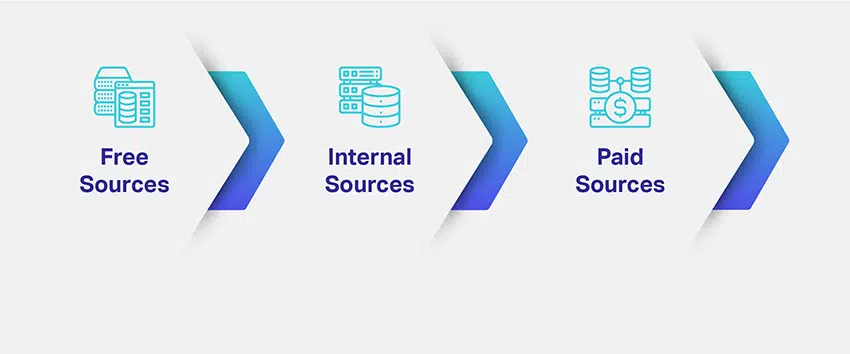
Miten huonot tiedot vaikuttavat tekoälyn tavoitteisiisi?
Listasimme kolme yleisintä tietoresurssia, koska sinulla on käsitys tiedon keräämisestä ja hankinnasta. Tässä vaiheessa on kuitenkin tärkeää ymmärtää, että päätöksesi voi poikkeuksetta päättää tekoälyratkaisusi kohtalosta.
Samalla tavalla kuin laadukkaat tekoälyharjoitustiedot voivat auttaa mallia tuottamaan tarkkoja ja oikea-aikaisia tuloksia, huonot harjoitustiedot voivat myös rikkoa tekoälymallejasi, vääristää tuloksia, aiheuttaa harhaa ja muita ei-toivottuja seurauksia.
Mutta miksi näin tapahtuu? Eikö minkään datan ole tarkoitus kouluttaa ja optimoida tekoälymalliasi? Rehellisesti, ei. Ymmärretään tämä tarkemmin.
Huono data – mitä se on?
 Virheellisiä tietoja ovat kaikki tiedot, jotka ovat epäolennaisia, virheellisiä, epätäydellisiä tai puolueellisia. Huonosti määriteltyjen tiedonkeruustrategioiden ansiosta useimmat datatieteilijät ja huomautusten asiantuntijat joutuvat työskentelemään huonojen tietojen parissa.
Virheellisiä tietoja ovat kaikki tiedot, jotka ovat epäolennaisia, virheellisiä, epätäydellisiä tai puolueellisia. Huonosti määriteltyjen tiedonkeruustrategioiden ansiosta useimmat datatieteilijät ja huomautusten asiantuntijat joutuvat työskentelemään huonojen tietojen parissa.
Strukturoimattoman ja huonon datan ero on se, että jäsentämättömän datan näkemyksiä on kaikkialla. Mutta pohjimmiltaan ne voivat olla hyödyllisiä riippumatta. Käyttämällä lisäaikaa datatutkijat voisivat silti poimia olennaista tietoa jäsentämättömistä tietojoukoista. Näin ei kuitenkaan ole huonojen tietojen kohdalla. Nämä tietojoukot eivät sisällä lainkaan tai rajoitetusti oivalluksia tai tietoja, jotka ovat arvokkaita tai tärkeitä tekoälyprojektillesi tai sen koulutustarkoituksiin.
Joten kun hankit tietojoukot ilmaisista resursseista tai sinulla on löyhästi muodostetut sisäiset tiedon kosketuspisteet, on erittäin todennäköistä, että lataat tai luot huonoja tietoja. Kun tutkijasi työskentelevät huonojen tietojen parissa, et vain tuhlaa ihmistunteja, vaan myös työnnät tuotteesi markkinoille.
Jos et vieläkään ole varma siitä, mitä huonot tiedot voivat vaikuttaa tavoitteisiisi, tässä on nopea luettelo:
- Käytät lukemattomia tunteja huonojen tietojen hankkimiseen ja tuhlaat tunteja, vaivaa ja rahaa resursseihin.
- Huono data voi aiheuttaa sinulle juridisia ongelmia, jos niitä ei huomaa, ja ne voivat heikentää tekoälysi tehokkuutta
malleja. - Kun otat tuotteesi käyttöön huonoihin tietoihin koulutettuna, se vaikuttaa käyttökokemukseen
- Huono data voi tehdä tuloksista ja johtopäätöksistä puolueellisia, mikä voi aiheuttaa vastareaktioita entisestään.
Joten jos mietit, löytyykö tähän ratkaisua, se on todellakin olemassa.
Tekoälyn koulutustiedon toimittajat auttamaan
 Yksi perusratkaisuista on valita datatoimittaja (maksulliset lähteet). Tekoälyn koulutusdatan tarjoajat varmistavat, että saamasi tiedot ovat tarkkoja ja osuvia, ja sinulle toimitetaan tietojoukot jäsennellyssä muodossa. Sinun ei tarvitse olla mukana portaalista portaaliin siirtymisessä tietojoukkojen etsimiseksi.
Yksi perusratkaisuista on valita datatoimittaja (maksulliset lähteet). Tekoälyn koulutusdatan tarjoajat varmistavat, että saamasi tiedot ovat tarkkoja ja osuvia, ja sinulle toimitetaan tietojoukot jäsennellyssä muodossa. Sinun ei tarvitse olla mukana portaalista portaaliin siirtymisessä tietojoukkojen etsimiseksi.
Sinun tarvitsee vain ottaa tiedot ja kouluttaa tekoälymallisi täydellisyyteen. Tämän jälkeen olemme varmoja, että seuraava kysymyksesi koskee tiedontoimittajien kanssa tehtävään yhteistyöhön liittyviä kustannuksia. Ymmärrämme, että jotkut teistä työskentelevät jo henkisen budjetin parissa, ja juuri siihen olemmekin menossa seuraavaksi.
Tekijät, jotka on otettava huomioon, kun päätät tehokkaan budjetin tiedonkeruuprojektillesi
Tekoälykoulutus on systemaattista lähestymistapaa ja siksi budjetointi on olennainen osa sitä. Tekijät, kuten sijoitetun pääoman tuotto, tulosten tarkkuus, koulutusmenetelmät ja paljon muuta, tulee ottaa huomioon, ennen kuin sijoittaa valtavasti rahaa tekoälyn kehittämiseen. Monet projektipäälliköt tai yritysten omistajat haparoivat tässä vaiheessa. He tekevät hätiköityjä päätöksiä, jotka tuovat peruuttamattomia muutoksia heidän tuotekehitysprosessiinsa ja pakottavat heidät lopulta kuluttamaan enemmän.
Tämä osio antaa kuitenkin sinulle oikeat näkemykset. Kun istut alas työstämään tekoälykoulutuksen budjettia, kolme asiaa tai tekijää ovat väistämättömiä.

Katsotaanpa kutakin yksityiskohtaisesti.
Tarvitsemasi tiedon määrä
Olemme koko ajan sanoneet, että tekoälymallisi tehokkuus ja tarkkuus riippuu siitä, kuinka paljon sitä on koulutettu. Tämä tarkoittaa, että mitä enemmän tietojoukkoja on, sitä enemmän oppimista. Mutta tämä on hyvin epämääräistä. Dimensional Research julkaisi tämän käsityksen numeron, joka paljasti, että yritykset tarvitsevat vähintään 100,000 XNUMX näyteaineistoa AI-malliensa kouluttamiseen.
100,000 100,000 tietojoukolla tarkoitamme XNUMX XNUMX laadukasta ja asiaankuuluvaa tietojoukkoa. Näissä tietojoukoissa tulee olla kaikki olennaiset attribuutit, huomautukset ja oivallukset, joita algoritmeillesi ja koneoppimismalleillesi tarvitaan tietojen käsittelemiseksi ja suunniteltujen tehtävien suorittamiseksi.
Tämä on yleinen nyrkkisääntö, joten ymmärrämme paremmin, että tarvitsemasi tiedon määrä riippuu myös toisesta monimutkaisesta tekijästä, joka on yrityksesi käyttötapaus. Se, mitä aiot tehdä tuotteellasi tai ratkaisullasi, määrittää myös tarvitsemasi tiedon määrän. Esimerkiksi suositusmoottoria rakentavalla yrityksellä on erilaiset tietomäärävaatimukset kuin chatbotia rakentavalla yrityksellä.
Datan hinnoittelustrategia
Kun olet päättänyt, kuinka paljon tietoja todella tarvitset, sinun on seuraavaksi työstettävä datan hinnoittelustrategiaa. Yksinkertaisesti sanottuna tämä tarkoittaa sitä, kuinka maksaisit hankkimistasi tai luomistasi tietojoukoista.
Yleisesti ottaen nämä ovat markkinoilla noudatettuja tavanomaisia hinnoittelustrategioita:
| Tietotyyppi | Hinnoittelustrategia |
|---|---|
| Hinnoiteltu yksittäistä kuvatiedostoa kohti | |
| Hinnoiteltu sekunnissa, minuutissa, tunnissa tai yksittäisessä kehyksessä | |
| Hinnoiteltu sekunnissa, minuutissa tai tunnissa | |
| Hinnoitettu per sana tai lause |
Mutta odota. Tämä on taas nyrkkisääntö. Tietojen hankinnan todelliset kustannukset riippuvat myös seuraavista tekijöistä:
- Ainutlaatuinen markkinasegmentti, demografiset tiedot tai maantiede, josta tietojoukot on hankittava
- Käyttötapasi monimutkaisuus
- Kuinka paljon dataa tarvitset?
- Sinun aikasi markkinoille
- Kaikki räätälöidyt vaatimukset ja paljon muuta
Jos huomaat, tiedät, että kustannukset suurten määrien kuvien hankkimisesta tekoälyprojektiisi voivat olla pienemmät, mutta jos sinulla on liikaa määrityksiä, hinnat voivat nousta.
Hankintastrategiasi
Tämä on hankalaa. Kuten näit, on olemassa erilaisia tapoja luoda tai hankkia tietoja tekoälymalleillesi. Maalaisjärki sanelee, että ilmaiset resurssit ovat parhaita, koska voit ladata vaaditut määrät tietojoukkoja ilmaiseksi ilman ongelmia.
Tällä hetkellä näyttää myös siltä, että maksulliset lähteet ovat liian kalliita. Mutta tähän lisätään monimutkaisuus. Kun hankit tietojoukkoja ilmaisista resursseista, käytät ylimääräistä aikaa ja vaivaa datajoukkojen puhdistamiseen, niiden kokoamiseen yrityskohtaiseen muotoon ja sitten merkintöihin yksitellen. Sinulle aiheutuu prosessista käyttökustannuksia.
Maksullisilla lähteillä maksu on kertaluonteinen ja saat myös konevalmiit tietojoukot käsiisi haluamaasi aikaan. Kustannustehokkuus on tässä hyvin subjektiivista. Jos sinusta tuntuu, että sinulla on varaa käyttää aikaa ilmaisten tietojoukkojen merkitsemiseen, voit budjetoida vastaavasti. Ja jos uskot, että kilpailusi on kovaa ja markkinoilletuloaika on rajoitettu, voit luoda heijastusvaikutuksen markkinoille, sinun kannattaa suosia maksullisia lähteitä.
Budjetoinnin tarkoituksena on eritellä yksityiskohdat ja määritellä selkeästi jokainen fragmentti. Näiden kolmen tekijän pitäisi toimia etenemissuunnitelmana tekoälykoulutuksesi budjetointiprosessissa tulevaisuudessa.
Säästätkö kustannuksissa sisäisen tiedonkeruun avulla?
 Budjetoinnin aikana tutkimme, kuinka vapaat resurssit pakottavat sinut kuluttamaan enemmän pitkällä aikavälillä. Siinä vaiheessa olisit automaattisesti ihmetellyt sisäisen tiedonhankintaprosessin kustannustehokkuutta.
Budjetoinnin aikana tutkimme, kuinka vapaat resurssit pakottavat sinut kuluttamaan enemmän pitkällä aikavälillä. Siinä vaiheessa olisit automaattisesti ihmetellyt sisäisen tiedonhankintaprosessin kustannustehokkuutta.
Tiedämme, että olet edelleen epäröivä maksullisten lähteiden suhteen, ja siksi tämä osio poistaa skeptisisyytesi sitä kohtaan ja valaisee sisäiseen tiedontuotantoon liittyviä piilokustannuksia.
Onko yrityksen sisäinen tiedonhankinta kallista?
Kyllä se on!
Tässä nyt seikkaperäinen vastaus. Kulut ovat mitä tahansa, mitä kulutat. Keskustellessamme ilmaisista resursseista paljasimme, että käytät rahaa, aikaa ja vaivaa prosessiin. Tämä koskee myös talon sisäistä tiedonkeruuta.
 Koska sinulla on mukautettuja kosketuspisteitä tai tietokanavia, se ei tarkoita, että sinulla olisi niitä konevalmiit tietojoukot lopussa. Luomasi data on edelleen enimmäkseen raakaa ja jäsentämätöntä. Sinulla saattaa olla kaikki tarvitsemasi tiedot yhdessä paikassa, mutta se, mitä tiedot sisältävät, on kaikkialla.
Koska sinulla on mukautettuja kosketuspisteitä tai tietokanavia, se ei tarkoita, että sinulla olisi niitä konevalmiit tietojoukot lopussa. Luomasi data on edelleen enimmäkseen raakaa ja jäsentämätöntä. Sinulla saattaa olla kaikki tarvitsemasi tiedot yhdessä paikassa, mutta se, mitä tiedot sisältävät, on kaikkialla.
Viime kädessä joudut maksamaan palkkaa työntekijöillesi, datatutkijoille, annotaattoreille, laadunvarmistuksen ammattilaisille ja muille. Kulutat myös merkintätyökalujen tilauksiin ja
CMS:n, CRM:n ja muiden infrastruktuurikustannusten ylläpitokulut.
Lisäksi tietojoukoissa on väistämättä harha- ja tarkkuusongelmia, jotka sinun on tarpeen lajitella ne manuaalisesti. Ja jos sinulla on kulumisongelmia tekoälyn koulutustiimissäsi, joudut käyttämään rahaa uusien jäsenten rekrytointiin, heidän ohjaamiseen prosesseihisi, heidän kouluttamiseen käyttämään työkalujasi ja paljon muuta.
Lopulta kulutat enemmän kuin mitä lopulta tienaat pidemmällä aikavälillä. Mukana on myös huomautuskuluja. Kulloinkin sisäisen tiedon käsittelystä aiheutuvat kokonaiskustannukset ovat:
Kertyneet kustannukset = Annotaattoreiden määrä * Kustannukset annotaattoria kohden + alustan kustannukset
Jos tekoälyharjoittelukalenterisi on suunniteltu kuukausiksi, kuvittele kulut, joita sinulle aiheutuisi jatkuvasti. Onko tämä siis ihanteellinen ratkaisu tiedonhankintaan vai onko olemassa vaihtoehtoa?
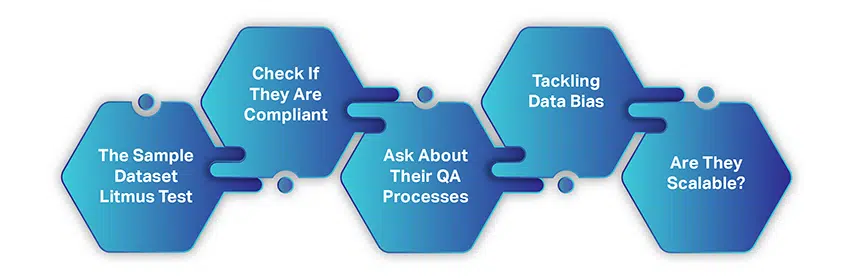
Kuinka valita oikea AI-tiedonkeruuyritys
AI-tiedonkeruuyrityksen valitseminen ei ole niin monimutkaista tai aikaa vievää kuin tiedon kerääminen ilmaisista resursseista. On vain muutamia yksinkertaisia tekijöitä, jotka sinun on otettava huomioon ja sitten kätteltävä yhteistyön aloittamiseksi.
Kun alat etsiä tietotoimittajaa, oletamme, että olet seurannut ja harkinnut kaikkea, mitä olemme tähän mennessä keskustelleet. Tässä kuitenkin lyhyt yhteenveto:
- Sinulla on hyvin määritelty käyttötapaus mielessäsi
- Markkinasegmenttisi ja tietovaatimukset ovat selkeät
- Budjettisi on kohdallaan
- Ja sinulla on käsitys tarvitsemasi tiedon määrästä
Kun nämä kohdat on valittuna, ymmärrämme, kuinka voit etsiä ihanteellista koulutusdatapalvelun tarjoajaa.