
esittely
Tämä opas on erittäin hyödyllinen niille ostajille ja päätöksentekijöille, jotka alkavat kääntää ajatuksensa tiedonhankinnan muttereihin ja pultteihin sekä hermoverkoissa että muun tyyppisissä tekoäly- ja ML-operaatioissa.

Tämä artikkeli on täysin omistettu valaisemaan mitä prosessi on, miksi se on väistämätöntä, ratkaisevaa
tekijöitä, jotka yritysten tulisi ottaa huomioon lähestyessään tietojen merkintätyökaluja ja paljon muuta. Joten jos omistat yrityksen, valmistaudu valaistumaan, koska tämä opas opastaa kaiken, mitä sinun tarvitsee tietää tietojen merkinnöistä.
Aloitetaan.
Niille teistä, jotka selaavat artikkelia, tässä on joitain nopeita otoksia, jotka löydät oppaasta:
- Ymmärrä mitä merkinnät ovat
- Tunne erityyppiset tietojen merkintäprosessit
- Tiedä tiedon merkintäprosessin toteuttamisen edut
- Saat selvyyttä siitä, kannattaako sinun käyttää sisäisiä tietomerkintöjä vai ulkoistaa ne
- Oivalluksia myös oikean tietomerkinnän valitsemisesta
Mikä on koneoppiminen?
 Olemme puhuneet siitä, miten tietojen merkinnät tai tietojen merkitseminen tukee koneoppimista ja että se koostuu komponenttien merkitsemisestä tai tunnistamisesta. Mutta mitä tulee syvään oppimiseen ja itse koneoppimiseen: koneoppimisen perusedellytys on, että tietokonejärjestelmät ja -ohjelmat voivat parantaa tuloksiaan kognitiivisia prosesseja muistuttavilla tavoilla ilman suoraa ihmisen apua tai väliintuloa. Toisin sanoen niistä tulee itseoppivia koneita, jotka, aivan kuten ihminen, tulevat paremmiksi työssään harjoittelemalla. Tämä "käytäntö" saadaan analysoimalla ja tulkitsemalla enemmän (ja parempia) koulutustietoja.
Olemme puhuneet siitä, miten tietojen merkinnät tai tietojen merkitseminen tukee koneoppimista ja että se koostuu komponenttien merkitsemisestä tai tunnistamisesta. Mutta mitä tulee syvään oppimiseen ja itse koneoppimiseen: koneoppimisen perusedellytys on, että tietokonejärjestelmät ja -ohjelmat voivat parantaa tuloksiaan kognitiivisia prosesseja muistuttavilla tavoilla ilman suoraa ihmisen apua tai väliintuloa. Toisin sanoen niistä tulee itseoppivia koneita, jotka, aivan kuten ihminen, tulevat paremmiksi työssään harjoittelemalla. Tämä "käytäntö" saadaan analysoimalla ja tulkitsemalla enemmän (ja parempia) koulutustietoja.
Mikä on tietojen merkintä?
Tietojen merkintä on prosessi, jossa tietoja määritetään, tunnistetaan tai merkitään, jotta koneoppimisalgoritmit ymmärtävät ja luokittelevat käsittelemänsä tiedot. Tämä prosessi on välttämätön tekoälymallien kouluttamisessa, jotta ne voivat ymmärtää tarkasti erilaisia tietotyyppejä, kuten kuvia, äänitiedostoja, videomateriaalia tai tekstiä.
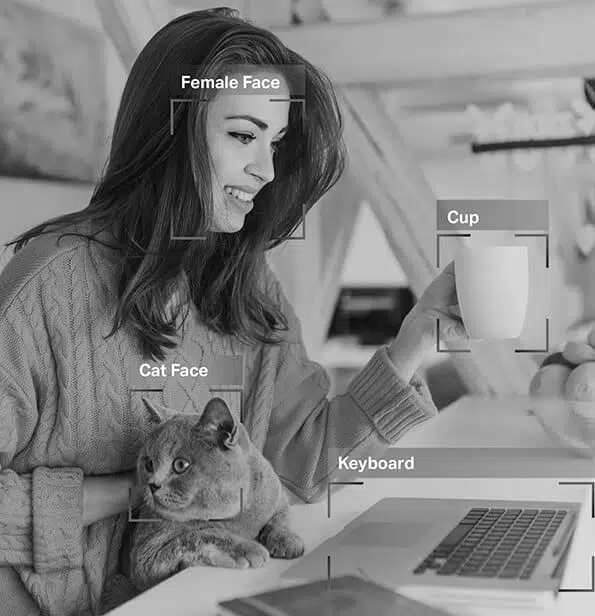
Kuvittele itse ajava auto, joka käyttää tietokonenäön, luonnollisen kielen käsittelyn (NLP) ja antureiden tietoja tehdäkseen tarkkoja ajopäätöksiä. Jotta auton tekoälymalli erottaa esteet, kuten muut ajoneuvot, jalankulkijat, eläimet tai tiesulut, sen vastaanottamat tiedot on merkittävä tai merkitty.
Ohjatussa oppimisessa datan annotointi on erityisen tärkeää, sillä mitä enemmän merkittyä dataa malliin syötetään, sitä nopeammin se oppii toimimaan itsenäisesti. Annotoidut tiedot mahdollistavat tekoälymallien käytön erilaisissa sovelluksissa, kuten chatboteissa, puheentunnistuksessa ja automaatiossa, mikä johtaa optimaaliseen suorituskykyyn ja luotettaviin tuloksiin.
Mikä on tietojen merkintä-/huomautustyökalu?
 Yksinkertaisesti sanottuna se on alusta tai portaali, jonka avulla asiantuntijat ja asiantuntijat voivat merkitä, merkitä tai merkitä kaikenlaisia tietojoukkoja. Se on silta tai väline raakadatan ja tulosten välillä, jotka koneoppimismoduulit lopulta tuhoavat.
Yksinkertaisesti sanottuna se on alusta tai portaali, jonka avulla asiantuntijat ja asiantuntijat voivat merkitä, merkitä tai merkitä kaikenlaisia tietojoukkoja. Se on silta tai väline raakadatan ja tulosten välillä, jotka koneoppimismoduulit lopulta tuhoavat.
Tietojen merkintätyökalu on ensipohjainen tai pilvipohjainen ratkaisu, joka merkitsee korkealaatuisia harjoitustietoja koneoppimismalleille. Vaikka monet yritykset luottavat monimutkaisiin merkintöihin ulkopuoliselta toimittajalta, joillakin organisaatioilla on edelleen omat työkalunsa, jotka on joko räätälöity tai jotka perustuvat markkinoilla oleviin ilmaisiin tai avoimiin työkaluihin. Tällaiset työkalut on yleensä suunniteltu käsittelemään tiettyjä tietotyyppejä, kuten kuvaa, videota, tekstiä, ääntä jne. Työkalut tarjoavat ominaisuuksia tai vaihtoehtoja, kuten rajauslaatikoita tai monikulmioita tietojen merkintöihin kuvien merkitsemiseksi. He voivat vain valita vaihtoehdon ja suorittaa erityistehtävänsä.
Kuvan merkintä

Koulutettujen tietojoukkojen perusteella he voivat erottaa silmäsi välittömästi ja tarkasti nenästäsi ja kulmakarvat ripsistäsi. Siksi käyttämäsi suodattimet sopivat täydellisesti riippumatta kasvosi muodosta, kuinka lähellä olet kameraasi ja paljon muuta.
Joten, kuten nyt tiedät, kuvan merkintä on elintärkeä moduuleissa, joihin kuuluu kasvojentunnistus, tietokonenäkö, robottinäkö ja paljon muuta. Kun AI -asiantuntijat kouluttavat tällaisia malleja, he lisäävät kuviin tekstityksiä, tunnisteita ja avainsanoja. Algoritmit tunnistavat ja ymmärtävät nämä parametrit ja oppivat itsenäisesti.
Kuvan luokitus - Kuvien luokittelussa kuville asetetaan ennalta määritettyjä luokkia tai tunnisteita niiden sisällön perusteella. Tämän tyyppistä merkintää käytetään AI-mallien opettamiseen tunnistamaan ja luokittelemaan kuvat automaattisesti.
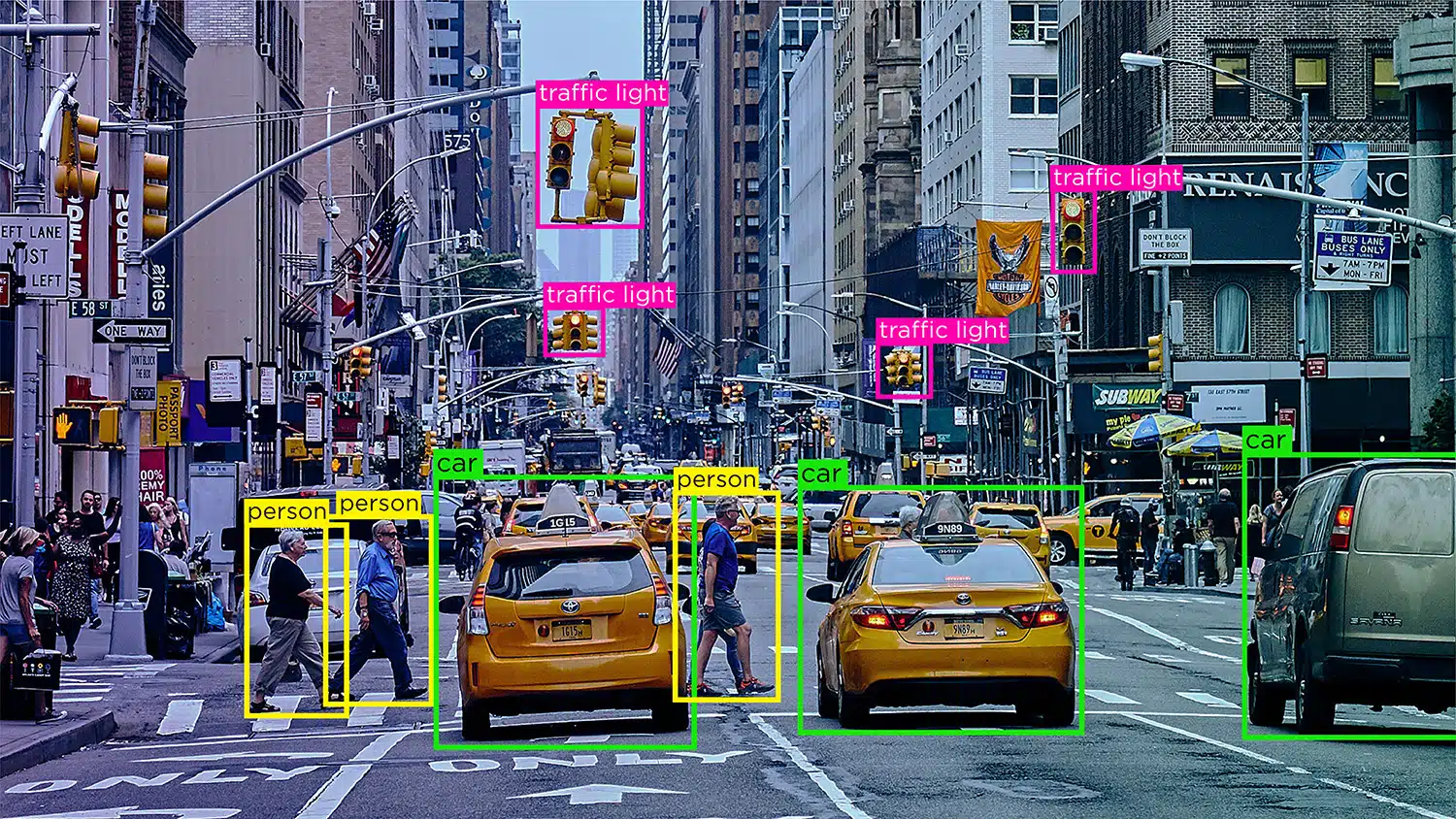
Objektin tunnistus/tunnistus – Objektin tunnistus eli objektin tunnistus on prosessi, jossa kuvassa olevat kohteet tunnistetaan ja merkitään. Tämän tyyppistä merkintää käytetään AI-mallien opettamiseen paikantamaan ja tunnistamaan esineitä todellisissa kuvissa tai videoissa.
jakautuminen – Kuvan segmentointi sisältää kuvan jakamisen useisiin segmentteihin tai alueisiin, joista jokainen vastaa tiettyä kohdetta tai kiinnostavaa aluetta. Tämän tyyppistä merkintää käytetään AI-mallien kouluttamiseen analysoimaan kuvia pikselitasolla, mikä mahdollistaa tarkemman kohteen tunnistuksen ja näkymän ymmärtämisen.
Äänimerkintä
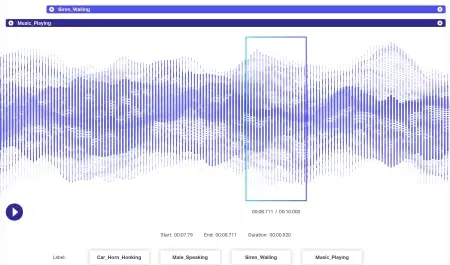
Äänidataan liittyy vielä enemmän dynamiikkaa kuin kuvadataan. Äänitiedostoon liittyy useita tekijöitä, muun muassa kieli, kaiuttimien väestötiedot, murteet, mieliala, tarkoitus, tunne, käyttäytyminen. Jotta algoritmit olisivat tehokkaita prosessoinnissa, kaikki nämä parametrit tulisi tunnistaa ja merkitä tekniikoilla, kuten aikaleimalla, äänimerkinnöillä ja muilla. Pelkästään sanallisten vihjeiden lisäksi sanattomat tapaukset, kuten hiljaisuus, hengitykset, jopa taustamelu voitaisiin merkitä järjestelmien ymmärtämiseksi kattavasti.
Videomerkintä

Vaikka kuva on paikallaan, video on kokoelma kuvia, jotka luovat vaikutuksen liikkeessä olevista esineistä. Nyt jokaista tämän kokoelman kuvaa kutsutaan kehykseksi. Videomerkinnän osalta prosessi sisältää avainpisteiden, monikulmioiden tai rajoittavien ruutujen lisäämisen, jotta jokaisessa kehyksessä voidaan merkitä kentän erilaisia objekteja.
Kun nämä kehykset ommellaan yhteen, tekoälymallit voivat oppia liikettä, käyttäytymistä, kuvioita ja paljon muuta. Se on vain läpi videomerkintä että sellaisia konsepteja kuin lokalisointi, liikkeen sumennus ja objektien seuranta voitaisiin toteuttaa järjestelmissä.
Tekstin merkintä

Nykyään useimmat yritykset luottavat tekstipohjaiseen dataan ainutlaatuisen oivalluksen ja tiedon saamiseksi. Nyt teksti voi olla mitä tahansa, aina asiakaspalautteesta sovelluksesta sosiaalisen median mainintaan. Ja toisin kuin kuvat ja videot, jotka välittävät enimmäkseen suoraviivaisia aikomuksia, tekstissä on paljon semantiikkaa.
Ihmisinä olemme virittyneet ymmärtämään lauseen kontekstia, jokaisen sanan, lauseen tai lauseen merkityksen, liittämään ne tiettyyn tilanteeseen tai keskusteluun ja ymmärtämään sitten lausunnon takana olevan kokonaisvaltaisen merkityksen. Toisaalta koneet eivät voi tehdä tätä tarkoilla tasoilla. Käsitteet, kuten sarkasmi, huumori ja muut abstraktit elementit, ovat heille tuntemattomia, ja siksi tekstitietojen merkitseminen vaikeutuu. Siksi tekstimerkinnöissä on joitain tarkempia vaiheita, kuten seuraavat:
Semanttinen merkintä - Kohteet, tuotteet ja palvelut tehdään merkityksellisemmiksi sopivilla avainsanailmaisinnoilla ja tunnisteparametreilla. Chatbotit tehdään myös matkimaan ihmisten keskusteluja tällä tavalla.
Tarkoitusmerkintä - käyttäjän tarkoitus ja käyttäjän käyttämä kieli on merkitty koneiden ymmärtämistä varten. Tämän avulla mallit voivat erottaa pyynnön komennosta tai suosituksen varauksesta ja niin edelleen.
Sentimenttimerkintä – Sentimenttimerkintä tarkoittaa tekstitietojen merkitsemistä sen välittämällä tunteella, kuten positiivinen, negatiivinen tai neutraali. Tämän tyyppistä merkintää käytetään yleisesti tunneanalyysissä, jossa tekoälymalleja koulutetaan ymmärtämään ja arvioimaan tekstissä ilmaistuja tunteita.

Entiteetin merkintä - jossa jäsentämättömät lauseet merkitään, jotta ne olisivat merkityksellisempiä ja saataisiin koneiden ymmärtämään muotoon. Tämän toteuttamiseksi on mukana kaksi näkökohtaa - nimetty kokonaisuuden tunnistus ja entiteetin linkittäminen. Nimetty entiteettitunnistus on, kun paikkojen, ihmisten, tapahtumien, organisaatioiden ja muiden nimitykset merkitään ja tunnistetaan, ja yksiköiden linkittäminen on, kun nämä tunnisteet linkitetään lauseisiin, lauseisiin, tosiseikkoihin tai mielipiteisiin, jotka seuraavat niitä. Nämä kaksi prosessia muodostavat yhdessä liittyvän tekstin ja sitä ympäröivän lausunnon välisen suhteen.
Tekstin luokittelu – Lauseet tai kappaleet voidaan merkitä ja luokitella yleisten aiheiden, suuntausten, aiheiden, mielipiteiden, luokkien (urheilu, viihde ja vastaavat) ja muiden parametrien perusteella.
Tietojen merkitsemis- ja huomautusprosessin tärkeimmät vaiheet
Tietojen merkintäprosessi sisältää sarjan hyvin määriteltyjä vaiheita, joilla varmistetaan korkealaatuinen ja tarkka datamerkintä koneoppimissovelluksille. Nämä vaiheet kattavat kaikki prosessin osa-alueet tietojen keräämisestä huomautusten sisältämien tietojen vientiin myöhempää käyttöä varten.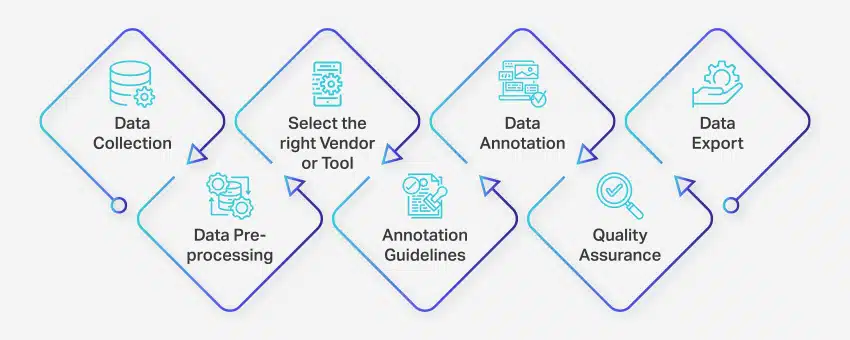
Näin tietojen merkitseminen tapahtuu:
- Tiedonkeruu: Ensimmäinen vaihe tietojen merkintäprosessissa on kerätä kaikki asiaankuuluvat tiedot, kuten kuvat, videot, äänitallenteet tai tekstidata, keskitettyyn paikkaan.
- Tietojen esikäsittely: Standardoi ja paranna kerättyä dataa vääristämällä kuvia, muotoilemalla tekstiä tai litteroimalla videosisältöä. Esikäsittely varmistaa, että tiedot ovat valmiita huomautuksia varten.
- Valitse oikea toimittaja tai työkalu: Valitse sopiva datamerkintätyökalu tai toimittaja projektisi vaatimusten perusteella. Vaihtoehtoihin kuuluvat alustat, kuten Nanonets tietojen merkintöihin, V7 kuvien merkintöihin, Appen videomerkintöihin ja Nanonets asiakirjamerkintöihin.
- Huomautuksia koskevat ohjeet: Luo selkeät ohjeet merkintöjen kirjoittajille tai merkintätyökaluille varmistaaksesi johdonmukaisuuden ja tarkkuuden koko prosessin ajan.
- Huomautukset: Merkitse ja merkitse tiedot käyttämällä ihmismerkintöjä tai tietomerkintäohjelmistoa annettujen ohjeiden mukaisesti.
- Laadunvarmistus (QA): Tarkista huomautetut tiedot tarkkuuden ja johdonmukaisuuden varmistamiseksi. Käytä tarvittaessa useita sokkomerkintöjä tulosten laadun varmistamiseksi.
- Tietojen vienti: Vie tiedot vaaditussa muodossa, kun tietomerkintä on valmis. Nanonetsien kaltaiset alustat mahdollistavat saumattoman tietojen viennin erilaisiin yritysohjelmistosovelluksiin.
Koko tietojen merkintäprosessi voi kestää muutamasta päivästä useisiin viikkoihin riippuen projektin koosta, monimutkaisuudesta ja käytettävissä olevista resursseista.
Ominaisuudet tietojen merkinnöille ja tietojen merkintätyökaluille
Tietojen merkintätyökalut ovat ratkaisevia tekijöitä, jotka voivat tehdä tai rikkoa tekoälyprojektisi. Tarkkojen tulosten ja tulosten osalta aineistojen laadulla ei ole väliä. Itse asiassa tietokommenttityökalut, joita käytät tekoälymoduuliesi kouluttamiseen, vaikuttavat valtavasti tuotoksiin.
Siksi on tärkeää valita ja käyttää kaikkein toimivinta ja sopivinta datan merkintatyökalua, joka vastaa yrityksesi tai projektisi tarpeita. Mutta mikä on tietojen merkintätyökalu? Mitä tarkoitusta se palvelee? Onko mitään tyyppejä? Otetaanpa selvää.
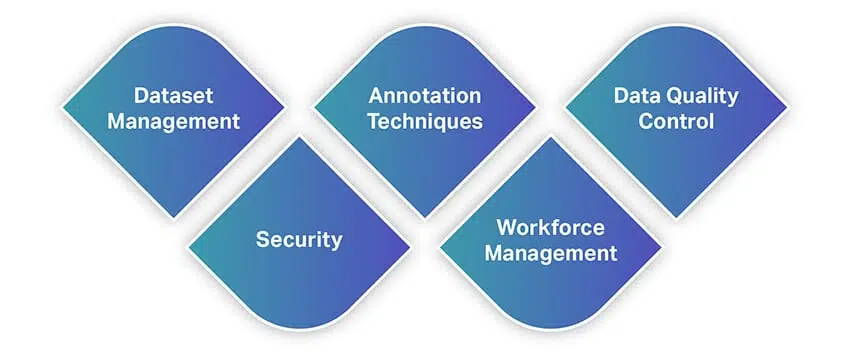
Kuten muutkin työkalut, tietojen merkintatyökalut tarjoavat laajan valikoiman ominaisuuksia ja ominaisuuksia. Jotta saat nopean käsityksen ominaisuuksista, tässä on luettelo tärkeimmistä ominaisuuksista, joita sinun tulee etsiä, kun valitset datan merkintätyökalun.
Tietojoukon hallinta
Tietojen merkintatyökalun, jota aiot käyttää, on tuettava käsilläsi olevia tietojoukkoja ja voit tuoda ne ohjelmistoon merkintöjä varten. Joten tietojoukkojen hallinta on ensisijainen työkalutarjous. Nykyaikaiset ratkaisut tarjoavat ominaisuuksia, joiden avulla voit tuoda suuria tietomääriä saumattomasti ja samalla järjestää tietojoukkoja esimerkiksi lajittelun, suodattamisen, kloonaamisen, yhdistämisen ja muiden toimintojen avulla.
Kun tietojoukko on syötetty, seuraavaksi viedään ne käyttökelpoisina tiedostoina. Käyttämäsi työkalun avulla voit tallentaa tietojoukot määrittämääsi muotoon, jotta voit syöttää ne ML -moduuleihisi.
Merkintätekniikat
Tätä varten tietojen merkintätyökalu on rakennettu tai suunniteltu. Kiinteän työkalun pitäisi tarjota sinulle erilaisia huomautustekniikoita kaikentyyppisille tietojoukoille. Tämä on, ellet kehitä mukautettua ratkaisua tarpeisiisi. Työkalusi avulla voit merkitä videoita tai kuvia tietokoneen visiosta, ääntä tai tekstiä NLP: stä ja transkriptioista ja paljon muuta. Tätä tarkentamalla edelleen pitäisi olla vaihtoehtoja rajauslaatikoiden, semanttisen segmentoinnin, kuutioiden, interpoloinnin, mielianalyysin, puheen osien, ydinratkaisuiden ja muiden käyttämiseen.
Aloittamattomille on myös tekoälykäyttöisiä datamerkintöjä. Näissä on tekoälymoduulit, jotka oppivat itsenäisesti merkintälaitteen työmalleista ja merkitsevät automaattisesti kuvia tai tekstiä. Sellainen
moduulien avulla voidaan tarjota uskomatonta apua annotaattoreille, optimoida huomautuksia ja jopa toteuttaa laaduntarkastuksia.
Tietojen laadunvalvonta
Laaduntarkastuksista puheen ollen, useita datan merkintatyökaluja on saatavana upotetuilla laaduntarkistusmoduuleilla. Niiden avulla merkinnät voivat tehdä parempaa yhteistyötä tiiminsä jäsenten kanssa ja optimoida työnkulut. Tämän ominaisuuden avulla huomautukset voivat merkitä ja seurata kommentteja tai palautetta reaaliajassa, seurata henkilöiden henkilöitä, jotka tekevät muutoksia tiedostoihin, palauttaa aiemmat versiot, valita konsensusmerkinnät ja paljon muuta.
Turvallisuus
Koska käsittelet tietoja, tietoturvan pitäisi olla etusijalla. Saatat käsitellä luottamuksellisia tietoja, kuten henkilötietoja tai immateriaalioikeuksia. Työkalusi on siis tarjottava ilmatiivis turvallisuus tietojen säilyttämiselle ja jakamiselle. Sen on tarjottava työkaluja, jotka rajoittavat pääsyä tiimin jäsenille, estävät luvattomat lataukset ja paljon muuta.
Näiden lisäksi turvallisuusstandardeja ja protokollia on noudatettava ja noudatettava.
Työvoiman hallinta
Tietojen merkintatyökalu on myös eräänlainen projektinhallinta -alusta, jossa tehtäviä voidaan antaa tiimin jäsenille, tehdä yhteistyötä, tehdä arviointeja ja paljon muuta. Siksi työkalun tulisi sopia työnkulkuun ja prosessiin tuottavuuden optimoimiseksi.
Lisäksi työkalulla on oltava myös minimaalinen oppimiskäyrä, koska tietojen merkitseminen itsessään on aikaa vievää. Se ei palvele mitään tarkoitusta viettää liikaa aikaa yksinkertaisesti työkalun oppimiseen. Joten sen pitäisi olla intuitiivista ja saumatonta, jotta kuka tahansa voi aloittaa nopeasti.
Mitä etuja datamerkinnöistä on?
Tietojen merkinnät ovat ratkaisevan tärkeitä koneoppimisjärjestelmien optimoinnissa ja paremman käyttökokemuksen tarjoamisessa. Tässä on joitain tietomerkintöjen tärkeimpiä etuja:
- Parempi koulutustehokkuus: Tietojen merkitseminen auttaa koneoppimismalleja kouluttamaan paremmin, mikä parantaa yleistä tehokkuutta ja tuottaa tarkempia tuloksia.
- Lisääntynyt tarkkuus: Tarkasti merkityt tiedot varmistavat, että algoritmit voivat mukautua ja oppia tehokkaasti, mikä parantaa tulevien tehtävien tarkkuutta.
- Vähentynyt ihmisen puuttuminen: Kehittyneet datamerkintätyökalut vähentävät merkittävästi manuaalisten toimenpiteiden tarvetta, virtaviivaistavat prosesseja ja vähentävät niihin liittyviä kustannuksia.
Näin ollen datamerkinnät edistävät tehokkaampia ja tarkempia koneoppimisjärjestelmiä ja minimoivat kustannukset ja manuaalisen vaivan, jota perinteisesti tarvitaan tekoälymallien kouluttamiseen.
Tietomerkintätyökalun luominen tai rakentamatta jättäminen
Yksi kriittinen ja kattava asia, joka voi tulla esiin tietomerkinnöissä tai tietojen merkitsemisprojektissa, on valinta joko rakentaa tai ostaa toimintoja näille prosesseille. Tämä voi tulla esiin useita kertoja projektin eri vaiheissa tai liittyä ohjelman eri osiin. Valinta on mahdollista rakentaa järjestelmä sisäisesti vai luottaa toimittajiin, on aina kompromissi.

Kuten voit todennäköisesti nyt kertoa, tietojen merkintä on monimutkainen prosessi. Samalla se on myös subjektiivinen prosessi. Tarkoituksena on, että ei ole olemassa yhtä ainoaa vastausta kysymykseen siitä, pitäisikö sinun ostaa tai rakentaa tietomerkintätyökalu. Paljon tekijöitä on otettava huomioon, ja sinun on kysyttävä itseltäsi joitain kysymyksiä ymmärtääksesi vaatimuksesi ja ymmärtääksesi, onko sinun todella ostettava tai rakennettava sellainen.
Tämän yksinkertaistamiseksi tässä on joitain tekijöitä, jotka sinun tulisi ottaa huomioon.
Sinun tavoitteesi
Ensimmäinen elementti, jonka sinun on määriteltävä, on tavoite tekoälyn ja koneoppimiskonseptien avulla.
- Miksi otat ne käyttöön yrityksessäsi?
- Ratkaisevatko ne asiakkaidesi todellisen ongelman?
- Tekevätkö he mitään käyttöliittymää vai taustaprosessia?
- Käytätkö tekoälyä uusien ominaisuuksien esittelyyn tai nykyisen verkkosivustosi, sovelluksen tai moduulin optimointiin?
- Mitä kilpailijasi tekee segmentilläsi?
- Onko sinulla tarpeeksi käyttötapauksia, jotka tarvitsevat tekoälyn puuttumista?
Vastaukset näihin kokoavat ajatuksesi - joita voi tällä hetkellä olla kaikkialla - yhteen paikkaan ja antaa sinulle enemmän selkeyttä.
AI -tiedonkeruu / lisensointi
Tekoälymallit vaativat vain yhden elementin toimiakseen - dataa. Sinun on tunnistettava, mistä voit tuottaa valtavia määriä totuustietoa. Jos yrityksesi tuottaa suuria määriä dataa, joka on käsiteltävä saadakseen tärkeitä tietoja liiketoiminnasta, toiminnasta, kilpailijoiden tutkimuksesta, markkinoiden epävakausanalyysistä, asiakkaiden käyttäytymistutkimuksesta ja muusta, tarvitset tietojen merkintatyökalun. Kannattaa kuitenkin ottaa huomioon myös tuottamasi datamäärä. Kuten aiemmin mainittiin, tekoälymalli on vain yhtä tehokas kuin syötettävän datan laatu ja määrä. Joten päätöksesi pitäisi aina riippua tästä tekijästä.
Jos sinulla ei ole oikeita tietoja ML-malliesi kouluttamiseen, myyjät voivat olla varsin käteviä ja auttavat sinua oikeuttamaan ML-mallien kouluttamiseen tarvittavat tiedot. Joissakin tapauksissa osa toimittajan tuomasta arvosta sisältää sekä teknisen kyvyn että pääsyn resursseihin, jotka edistävät projektin menestystä.
talousarvio
Toinen perusedellytys, joka todennäköisesti vaikuttaa kaikkiin yksittäisiin tekijöihin, joista parhaillaan keskustelemme. Ratkaisu kysymykseen siitä, pitäisikö tietolähde rakentaa vai ostaa, on helppoa, kun ymmärrät, onko sinulla riittävästi budjettia kuluttamiseen.
Vaatimustenmukaisuuden monimutkaisuus
 Toimittajat voivat olla erittäin hyödyllisiä tietosuojaan ja arkaluonteisten tietojen oikeaan käsittelyyn liittyen. Yksi tällaisista käyttötapauksista koskee sairaalaa tai terveydenhoitoon liittyvää yritystä, joka haluaa hyödyntää koneoppimisen voimaa vaarantamatta sen noudattamista HIPAA: n ja muiden tietosuojasääntöjen mukaisesti. Jopa lääketieteen ulkopuolelta Euroopan GDPR: n kaltaiset lait kiristävät tietojoukkojen valvontaa ja vaativat suurempaa valppautta yrityksen sidosryhmiltä.
Toimittajat voivat olla erittäin hyödyllisiä tietosuojaan ja arkaluonteisten tietojen oikeaan käsittelyyn liittyen. Yksi tällaisista käyttötapauksista koskee sairaalaa tai terveydenhoitoon liittyvää yritystä, joka haluaa hyödyntää koneoppimisen voimaa vaarantamatta sen noudattamista HIPAA: n ja muiden tietosuojasääntöjen mukaisesti. Jopa lääketieteen ulkopuolelta Euroopan GDPR: n kaltaiset lait kiristävät tietojoukkojen valvontaa ja vaativat suurempaa valppautta yrityksen sidosryhmiltä.
Työvoima
Tietojen merkinnät edellyttävät ammattitaitoista työvoimaa työskennelläksesi yrityksesi koosta, laajuudesta ja toimialueesta riippumatta. Vaikka tuotat vähimmäistietoja joka päivä, tarvitset data -asiantuntijoita käsittelemään tietojasi merkintöjä varten. Joten nyt sinun on ymmärrettävä, onko sinulla tarvittava työvoima. Jos sinulla on, ovatko he taitavia vaadittujen työkalujen ja tekniikoiden kanssa tai tarvitsevatko he ammattitaitoa? Jos he tarvitsevat taitoja, onko sinulla riittävästi rahaa kouluttaa heitä?
Lisäksi parhaat tietomerkintä- ja merkintäjärjestelmät vievät useita aihe- tai toimialan asiantuntijoita ja segmentoivat ne väestötietojen, kuten iän, sukupuolen ja osaamisalueen mukaan - tai usein niiden lokalisoitujen kielten mukaan, joiden kanssa he työskentelevät. Tässä taas kerran Shaipissa puhumme oikeiden ihmisten saamisesta oikeille istuimille ja ajamme siten oikeat silmukka-prosessit, jotka johtavat ohjelmalliset ponnistuksesi menestykseen.
Pienet ja suuret projektitoiminnot ja kustannusrajat
Monissa tapauksissa myyjän tuki voi olla enemmän vaihtoehto pienempää projektia tai pienempiä projektivaiheita varten. Kun kustannukset ovat hallittavissa, yritys voi hyötyä ulkoistamisesta tehostaakseen tietojen merkintöjä tai merkintöjä.
Yritykset voivat myös tarkastella tärkeitä kynnysarvoja - joissa monet toimittajat sitovat kustannukset kulutettuun tietomäärään tai muihin resurssien vertailuarvoihin. Oletetaan esimerkiksi, että yritys on tilannut toimittajan kanssa testausjoukkojen määrittämiseen vaadittavan ikävän tietojen syöttämisen.
Sopimuksessa voi olla piilotettu kynnys, jossa esimerkiksi liikekumppanin on otettava uusi AWS-tietojen tallennustila tai jokin muu palvelukomponentti Amazon Web Services -palvelusta tai joku muu kolmannen osapuolen toimittaja. Ne välittävät sen asiakkaalle suurempien kustannusten muodossa, ja se asettaa hintalappun asiakkaan ulottumattomiin.
Näissä tapauksissa toimittajilta saamiesi palveluiden mittaaminen auttaa pitämään projektin kohtuuhintaisena. Oikean soveltamisalan varmistaminen varmistaa, että projektikustannukset eivät ylitä sitä, mikä on kohtuullista tai mahdollista yritykselle.
Avoimen lähdekoodin ja ilmaisohjelmien vaihtoehdot
 Jotkut vaihtoehdot toimittajan täydelle tuelle sisältävät avoimen lähdekoodin ohjelmistojen tai jopa ilmaisten ohjelmistojen käyttämisen tietojen merkitsemiseen tai merkitsemiseen. Tässä on eräänlainen keskitie, jossa yritykset eivät luo kaikkea tyhjästä, mutta myös välttävät turvautumasta liikaa kaupallisiin myyjiin.
Jotkut vaihtoehdot toimittajan täydelle tuelle sisältävät avoimen lähdekoodin ohjelmistojen tai jopa ilmaisten ohjelmistojen käyttämisen tietojen merkitsemiseen tai merkitsemiseen. Tässä on eräänlainen keskitie, jossa yritykset eivät luo kaikkea tyhjästä, mutta myös välttävät turvautumasta liikaa kaupallisiin myyjiin.
Avoimen lähdekoodin tee-se-itse-mentaliteetti on sinänsä eräänlainen kompromissi - insinöörit ja sisäiset ihmiset voivat hyödyntää avoimen lähdekoodin yhteisöä, jossa hajautetut käyttäjäkannat tarjoavat omat ruohonjuuritason tukensa. Se ei ole kuin mitä saat myyjältä - et saa ympärivuorokautista apua tai vastauksia kysymyksiin tekemättä sisäistä tutkimusta - mutta hintalappu on alhaisempi.
Joten iso kysymys - milloin sinun pitäisi ostaa tietojen merkintätyökalu:
Kuten monenlaisten korkean teknologian projektien kohdalla, tämän tyyppinen analyysi - milloin rakentaa ja milloin ostaa - vaatii omistautunutta ajattelua ja harkintaa näiden hankkeiden hankinnasta ja hallinnasta. Haasteet, joita useimmat yritykset kohtaavat tekoälyn / ML-hankkeisiin liittyen harkita "rakentaa" -vaihtoehtoa, ei ole kyse pelkästään projektin rakentamisesta ja kehittämisestä. Usein on valtava oppimiskäyrä päästäksesi siihen pisteeseen, jossa todellinen tekoälyn / ML-kehitys voi tapahtua. Uusilla tekoäly / ML-ryhmillä ja aloitteilla tuntemattomien tuntematon määrä on huomattavasti suurempi kuin tunnettujen tuntemattomien määrä.
| Rakentaa | Ostaa |
|---|---|
Plussat:
| Plussat:
|
Miinukset:
| Miinukset:
|
Harkitse seuraavia asioita, jotta asiat olisivat vielä yksinkertaisempia:
- kun työskentelet valtavien tietomäärien parissa
- kun työskentelet monenlaisten tietojen kanssa
- kun malleihisi tai ratkaisuihisi liittyvät toiminnot voivat muuttua tai kehittyä tulevaisuudessa
- kun sinulla on epämääräinen tai yleinen käyttötapaus
- kun tarvitset selkeän kuvan tietojen merkintätyökalun käyttöönoton kustannuksista
- ja kun sinulla ei ole oikeaa työvoimaa tai ammattitaitoisia asiantuntijoita työskentelemään työkalujen parissa ja etsit minimaalista oppimiskäyrää
Jos vastauksesi olivat päinvastaisia kuin nämä skenaariot, sinun tulisi keskittyä työkalun rakentamiseen.
Kuinka valita oikea datamerkintätyökalu projektillesi
Jos luet tätä, nämä ideat kuulostavat jännittäviltä, ja ne on ehdottomasti helpompi sanoa kuin tehdä. Joten miten voidaan hyödyntää lukuisia jo olemassa olevia tietojen merkintätyökaluja siellä? Joten seuraavassa vaiheessa tarkastellaan tekijöitä, jotka liittyvät oikean tietomerkintätyökalun valitsemiseen.
Toisin kuin muutama vuosi sitten, markkinat ovat kehittyneet monien tietojen merkintätyökalujen avulla käytännössä tänään. Yrityksillä on enemmän vaihtoehtoja valita yksi niiden erillisten tarpeiden perusteella. Mutta jokaisella työkalulla on omat etunsa ja haittansa. Viisaan päätöksen tekemiseksi on myös erotettava objektiivinen reitti subjektiivisten vaatimusten lisäksi.
Katsotaanpa joitain keskeisiä tekijöitä, jotka sinun tulisi ottaa huomioon prosessissa.
Käyttötapauksen määrittäminen
Oikean tietomerkintätyökalun valitsemiseksi sinun on määritettävä käyttötapasi. Sinun tulisi ymmärtää, jos vaatimus sisältää tekstiä, kuvaa, videota, ääntä tai sekoitusta kaikista tietotyypeistä. On olemassa erillisiä työkaluja, joita voit ostaa, ja on kokonaisvaltaisia työkaluja, joiden avulla voit suorittaa erilaisia toimia tietojoukoilla.
Nykyiset työkalut ovat intuitiivisia ja tarjoavat sinulle vaihtoehtoja tallennustilojen (verkko, paikallinen tai pilvi), merkintätekniikoiden (ääni, kuva, 3D ja muut) ja joukon muita näkökohtia varten. Voit valita työkalun erityistarpeidesi mukaan.
Laadunvalvontastandardien laatiminen
 Tämä on ratkaiseva tekijä, joka on otettava huomioon, koska tekoälymalliesi tarkoitus ja tehokkuus riippuvat asettamistasi laatustandardeista. Kuten auditointi, sinun on suoritettava syötettyjen tietojen ja saatujen tulosten laatutarkastukset, jotta ymmärrät, koulutetaanko mallejasi oikealla tavalla ja oikeisiin tarkoituksiin. Kysymys on kuitenkin siitä, miten aiot laatia laatustandardit?
Tämä on ratkaiseva tekijä, joka on otettava huomioon, koska tekoälymalliesi tarkoitus ja tehokkuus riippuvat asettamistasi laatustandardeista. Kuten auditointi, sinun on suoritettava syötettyjen tietojen ja saatujen tulosten laatutarkastukset, jotta ymmärrät, koulutetaanko mallejasi oikealla tavalla ja oikeisiin tarkoituksiin. Kysymys on kuitenkin siitä, miten aiot laatia laatustandardit?
Kuten monien erilaisten töiden kohdalla, monet ihmiset voivat tehdä tietojen merkinnät ja tunnisteet, mutta he tekevät sen eriasteisella menestyksellä. Kun pyydät palvelua, et tarkista automaattisesti laadunvalvonnan tasoa. Siksi tulokset vaihtelevat.
Joten, haluatko ottaa käyttöön konsensusmallin, jossa merkintäjät tarjoavat palautetta laadusta ja korjaavat toimenpiteet toteutetaan välittömästi? Vai pidätkö mieluummin näytekatsauksesta, kultastandardeista tai risteyksestä kuin unionimallit?
Paras ostosuunnitelma varmistaa, että laadunvalvonta on käytössä alusta alkaen asettamalla standardit ennen lopullisesta sopimuksesta sopimista. Tätä määritettäessä ei pidä unohtaa myös virhemarginaaleja. Manuaalista puuttumista ei voida täysin välttää, koska järjestelmät tuottavat virheitä jopa 3 prosentin verran. Tämä vie työn etukäteen, mutta se on sen arvoista.
Kuka merkitsee tietosi?
Seuraava tärkeä tekijä riippuu siitä, kuka merkitsee tietosi. Aiotteko omistaa oman yrityksen tai haluaisitko mieluummin ulkoistaa sen? Jos olet ulkoistamassa, sinun on otettava huomioon laillisuudet ja noudattamistoimenpiteet, koska tietoihin liittyy yksityisyyttä ja luottamuksellisuutta. Ja jos sinulla on sisäinen tiimi, kuinka tehokkaasti he oppivat uuden työkalun? Mikä on aika markkinoida tuotetta tai palvelua? Onko sinulla oikeat laatumittarit ja tiimit tulosten hyväksymiseen?
Toimittaja vs. Kumppanikeskustelu
 Tietomerkinnät ovat yhteistyöprosessi. Siihen liittyy riippuvuuksia ja monimutkaisuutta, kuten yhteentoimivuus. Tämä tarkoittaa, että tietyt tiimit työskentelevät aina rinnakkain keskenään ja yksi joukkueista voi olla myyjäsi. Siksi valitsemasi myyjä tai kumppani on yhtä tärkeä kuin työkalu, jota käytät tietojen merkitsemiseen.
Tietomerkinnät ovat yhteistyöprosessi. Siihen liittyy riippuvuuksia ja monimutkaisuutta, kuten yhteentoimivuus. Tämä tarkoittaa, että tietyt tiimit työskentelevät aina rinnakkain keskenään ja yksi joukkueista voi olla myyjäsi. Siksi valitsemasi myyjä tai kumppani on yhtä tärkeä kuin työkalu, jota käytät tietojen merkitsemiseen.
Tässä tekijässä on otettava huomioon tekijät, kuten kyky pitää tietosi ja aikomuksesi luottamuksellisina, aikomus hyväksyä palautetta ja työskennellä sen kanssa, ennakoivuus tietojen hankkimisessa, toiminnan joustavuus ja paljon muuta, ennen kuin kättelet myyjää tai kumppania . Olemme sisällyttäneet joustavuuden, koska tietojen merkintävaatimukset eivät ole aina lineaarisia tai staattisia. Ne saattavat muuttua tulevaisuudessa, kun laajennat yritystäsi. Jos olet tällä hetkellä tekemisissä vain tekstipohjaisten tietojen kanssa, kannattaa ehkä merkitä ääni- tai videotiedot skaalattaessa, ja tukesi tulisi olla valmis laajentamaan heidän näköalojaan kanssasi.
Toimittajan osallistuminen
Yksi tavoista arvioida toimittajien osallistumista on saamasi tuki.
Kaikissa ostosuunnitelmissa on otettava huomioon tämä komponentti. Millainen tuki näyttää kentältä? Keitä sidosryhmät ja kohtaavat ihmiset ovat yhtälön molemmin puolin?
On myös konkreettisia tehtäviä, joiden on täsmennettävä myyjän osallistuminen (tai tulee olemaan). Tarjoaako myyjä aktiivisesti raakatietoja etenkin tietomerkinnöille tai etikettiprojekteille? Kuka toimii aiheen asiantuntijoina ja kuka palkkaa heidät joko työntekijöinä tai itsenäisinä urakoitsijoina?
Tapaustutkimuksia
Seuraavassa on muutamia esimerkkejä tapaustutkimuksista, joissa käsitellään sitä, miten tietojen merkinnät ja tietojen merkinnät todella toimivat käytännössä. Shaip huolehtii siitä, että tarjoamme korkeimman laadun ja erinomaiset tulokset tietojen merkinnöissä ja tietojen merkinnöissä.
Suuri osa yllä olevasta keskustelusta tietojen merkintöjen ja merkintöjen standardisaavutuksista paljastaa, miten lähestymme kutakin projektia ja mitä tarjoamme yrityksille ja sidosryhmille, joiden kanssa työskentelemme.
Tapaustutkimusmateriaalit, jotka osoittavat, miten tämä toimii:

Kliinisten tietojen lisensointiprojektissa Shaip-tiimi käsitteli yli 6,000 tuntia ääntä, poisti kaikki suojatut terveystiedot (PHI) ja jättivät HIPAA-yhteensopivan sisällön terveydenhuollon puheentunnistusmalleihin.
Tämän tyyppisissä tapauksissa kriteerit ja saavutusten luokittelu ovat tärkeitä. Raakatiedot ovat äänen muodossa, ja osapuolet on tunnistettava. Esimerkiksi NER-analyysin avulla kaksoistavoitteena on tunnistaa ja merkitä sisältö.
Toinen tapaustutkimus sisältää syvällisen keskustelulliset AI-harjoitustiedot projekti, jonka saimme päätökseen 3,000 14 lingvistin kanssa 27 viikon aikana. Tämä johti koulutusdatan tuottamiseen XNUMX kielellä, jotta voidaan kehittää monikielisiä digitaalisia avustajia, jotka pystyvät käsittelemään ihmisten vuorovaikutusta laajalla valikoimalla äidinkieliä.
Tässä nimenomaisessa tapaustutkimuksessa tarve saada oikea henkilö oikeaan tuoliin oli ilmeinen. Aiheiden asiantuntijoiden ja sisällön syöttöoperaattoreiden suuri määrä tarkoitti organisaation ja menettelyjen yksinkertaistamista, jotta projekti saataisiin aikaan tietyllä aikataululla. Tiimimme pystyi voittamaan alan standardin suurella marginaalilla optimoimalla tiedonkeruun ja myöhemmät prosessit.
Muun tyyppiset tapaustutkimukset sisältävät esimerkiksi botin koulutusta ja tekstimerkintöjä koneoppimiseen. Jälleen kerran tekstimuodossa on edelleen tärkeää kohdella tunnistettuja osapuolia tietosuojalakien mukaisesti ja lajitella raakatiedot kohdennettujen tulosten saamiseksi.
Toisin sanoen, työskennellessään useiden tietotyyppien ja -muotojen välillä, Shaip on osoittanut saman tärkeän menestyksen soveltamalla samoja menetelmiä ja periaatteita sekä raakatietoihin että tietojen lisensointitapahtumiin.