

Mitä ovat suuret kielimallit?
Suuret kielimallit (LLM) ovat kehittyneitä tekoälyjärjestelmiä, jotka on suunniteltu käsittelemään, ymmärtämään ja luomaan ihmisen kaltaista tekstiä. Ne perustuvat syvään oppimistekniikoihin, ja ne on koulutettu valtaviin tietokokonaisuuksiin, jotka sisältävät yleensä miljardeja sanoja eri lähteistä, kuten verkkosivustoilta, kirjoista ja artikkeleista. Tämän laajan koulutuksen avulla LLM:t voivat ymmärtää kielen, kieliopin, kontekstin ja jopa yleistiedon joitakin näkökohtia.
Jotkut suositut LLM:t, kuten OpenAI:n GPT-3, käyttävät eräänlaista neuroverkkoa, jota kutsutaan muuntajaksi, jonka avulla ne voivat käsitellä monimutkaisia kielitehtäviä huomattavalla taidolla. Nämä mallit voivat suorittaa monenlaisia tehtäviä, kuten:
- Kysymyksiin vastaaminen
- Yhteenveto tekstiä
- Kielten kääntäminen
- Luodaan sisältöä
- Jopa interaktiivisiin keskusteluihin käyttäjien kanssa
Koska LLM:t kehittyvät jatkuvasti, niillä on suuret mahdollisuudet parantaa ja automatisoida erilaisia sovelluksia eri toimialoilla asiakaspalvelusta ja sisällöntuotannosta koulutukseen ja tutkimukseen. Ne herättävät kuitenkin myös eettisiä ja yhteiskunnallisia huolenaiheita, kuten puolueellinen käyttäytyminen tai väärinkäyttö, joihin on puututtava tekniikan kehittyessä.

Suosittuja esimerkkejä suurista kielimalleista
Tässä on muutamia merkittäviä esimerkkejä LLM:istä, joita käytetään laajalti eri toimialoilla:
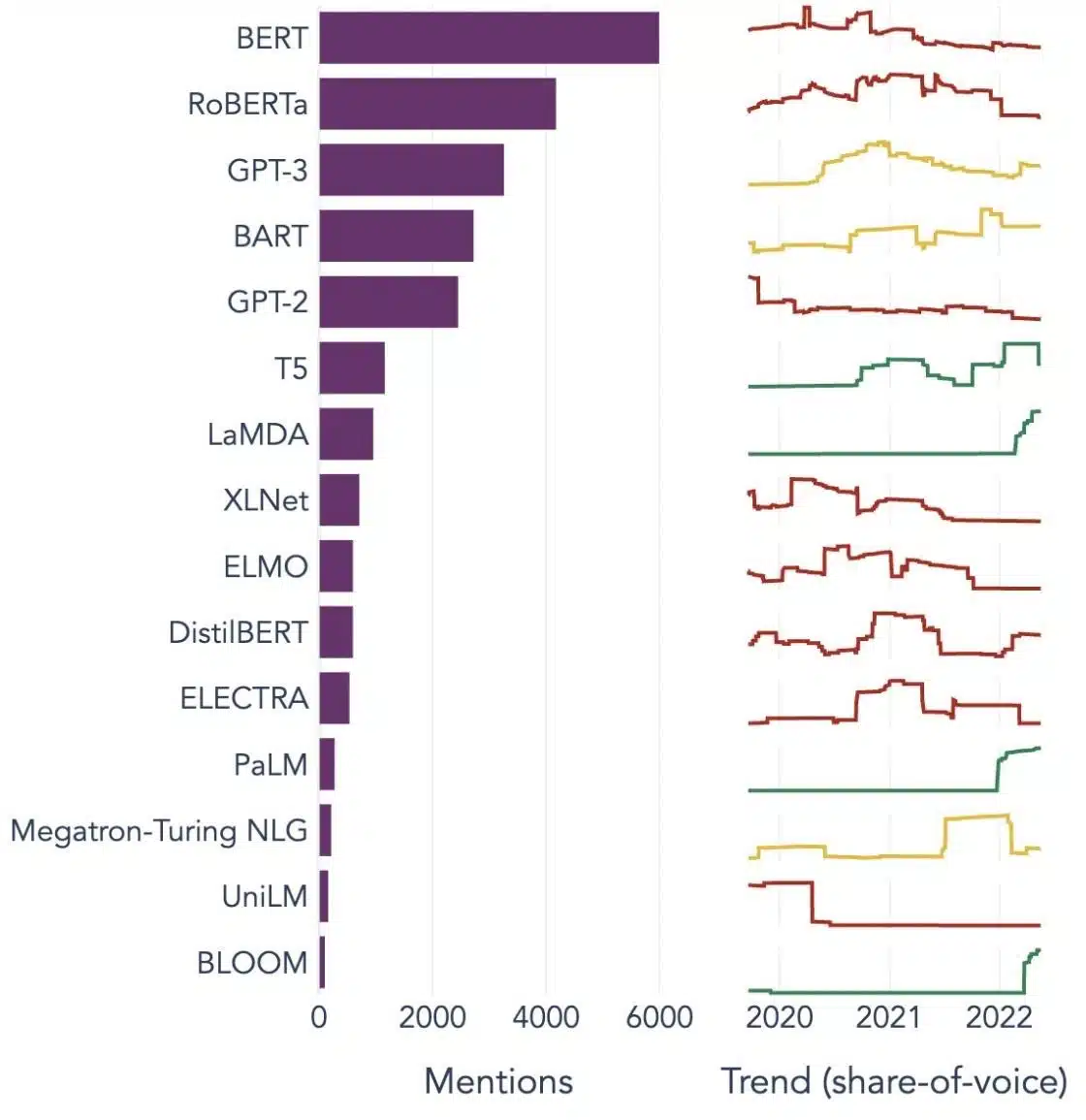
Image Source: Kohti datatieteitä
Miten LLM-malleja koulutetaan?
Suurten kielimallien (LLM) kouluttaminen on melkoinen saavutus, joka sisältää useita tärkeitä vaiheita. Tässä on yksinkertaistettu, vaiheittainen yhteenveto prosessista:
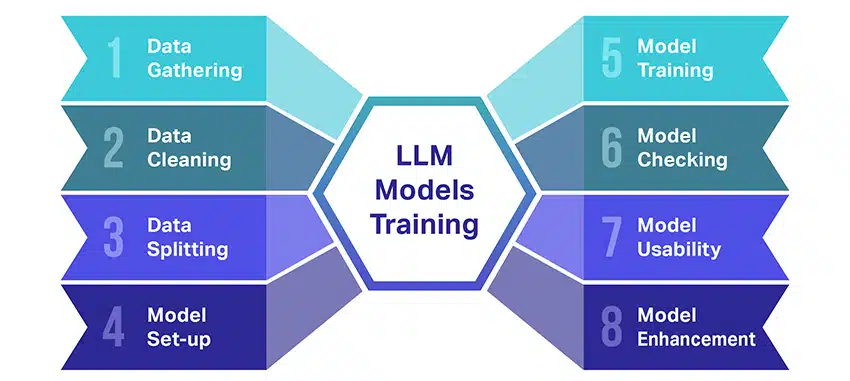
- Tekstitietojen kerääminen: LLM:n kouluttaminen alkaa suuren tekstidatan keräämisellä. Nämä tiedot voivat olla peräisin kirjoista, verkkosivustoilta, artikkeleista tai sosiaalisen median alustoista. Tavoitteena on vangita ihmisten kielen rikas monimuotoisuus.
- Tietojen puhdistaminen: Raakatekstidata siivotaan sitten prosessissa, jota kutsutaan esikäsittelyksi. Tähän sisältyy tehtäviä, kuten ei-toivottujen merkkien poistaminen, tekstin jakaminen pienempiin osiin, joita kutsutaan tunnuksiksi, ja kaiken saattaminen muotoon, jonka kanssa malli voi toimia.
- Tietojen jakaminen: Seuraavaksi puhtaat tiedot jaetaan kahteen ryhmään. Yhtä sarjaa, harjoitusdataa, käytetään mallin kouluttamiseen. Toista joukkoa, validointitietoja, käytetään myöhemmin mallin suorituskyvyn testaamiseen.
- Mallin asettaminen: Tämän jälkeen määritellään LLM:n rakenne, joka tunnetaan nimellä arkkitehtuuri. Tämä edellyttää hermoverkon tyypin valitsemista ja eri parametrien, kuten verkon kerrosten ja piilotettujen yksiköiden lukumäärän, päättämistä.
- Mallin koulutus: Varsinainen harjoittelu alkaa nyt. LLM-malli oppii tarkastelemalla harjoitustietoja, tekemällä ennusteita tähän mennessä oppimiensa tietojen perusteella ja säätämällä sitten sisäisiä parametrejaan pienentämään ennusteidensa ja todellisten tietojen välistä eroa.
- Mallin tarkistaminen: LLM-mallin oppiminen tarkistetaan validointidatan avulla. Tämä auttaa näkemään, kuinka hyvin malli toimii, ja säätämään mallin asetuksia suorituskyvyn parantamiseksi.
- Mallin käyttäminen: Koulutuksen ja arvioinnin jälkeen LLM-malli on käyttövalmis. Se voidaan nyt integroida sovelluksiin tai järjestelmiin, joissa se luo tekstiä annettujen uusien syötteiden perusteella.
- Mallin parantaminen: Lopuksi, aina on parantamisen varaa. LLM-mallia voidaan jalostaa edelleen ajan myötä käyttämällä päivitettyjä tietoja tai säätämällä asetuksia palautteen ja todellisen käytön perusteella.
Muista, että tämä prosessi vaatii merkittäviä laskentaresursseja, kuten tehokkaita prosessointiyksiköitä ja suurta tallennustilaa, sekä koneoppimisen erikoisosaamista. Siksi sen tekevät yleensä tutkimusorganisaatiot tai yritykset, joilla on pääsy tarvittavaan infrastruktuuriin ja asiantuntemukseen.
Luottaako LLM ohjattuun vai ohjaamattomaan oppimiseen?
Suuria kielimalleja koulutetaan yleensä käyttämällä menetelmää nimeltä ohjattu oppiminen. Yksinkertaisesti sanottuna tämä tarkoittaa, että he oppivat esimerkeistä, jotka osoittavat heille oikeat vastaukset.
 Kuvittele, että opetat lapselle sanoja näyttämällä heille kuvia. Näytät heille kuvan kissasta ja sanot "kissa", ja he oppivat yhdistämään kuvan sanaan. Näin ohjattu oppiminen toimii. Mallille annetaan paljon tekstiä ("kuvat") ja vastaavat tulosteet ("sanat"), ja se oppii sovittamaan niitä yhteen.
Kuvittele, että opetat lapselle sanoja näyttämällä heille kuvia. Näytät heille kuvan kissasta ja sanot "kissa", ja he oppivat yhdistämään kuvan sanaan. Näin ohjattu oppiminen toimii. Mallille annetaan paljon tekstiä ("kuvat") ja vastaavat tulosteet ("sanat"), ja se oppii sovittamaan niitä yhteen.
Joten jos syötät LLM:lle lauseen, se yrittää ennustaa seuraavan sanan tai lauseen sen perusteella, mitä se on oppinut esimerkeistä. Tällä tavalla se oppii luomaan järkevää ja kontekstiin sopivaa tekstiä.
Joskus LLM:t käyttävät kuitenkin myös vähän ohjaamatonta oppimista. Tämä on kuin antaisi lapsen tutustua huoneeseen, joka on täynnä erilaisia leluja ja oppia niistä itse. Malli tarkastelee merkitsemätöntä dataa, oppimismalleja ja rakenteita kertomatta "oikeita" vastauksia.
Valvottu oppiminen käyttää dataa, joka on merkitty syötteillä ja lähdöillä, toisin kuin ohjaamaton oppiminen, joka ei käytä merkittyjä lähtötietoja.
Lyhyesti sanottuna LLM:t koulutetaan pääasiassa ohjatun oppimisen avulla, mutta he voivat myös käyttää ohjaamatonta oppimista parantaakseen kykyjään, kuten tutkivaan analyysiin ja ulottuvuuksien vähentämiseen.
Mikä on suuren kielimallin kouluttamiseen tarvittava tietomäärä (Gt)?
Puhetietojen tunnistuksen ja puhesovellusten mahdollisuudet ovat valtavat, ja niitä käytetään useilla toimialoilla lukuisiin sovelluksiin.
Suuren kielimallin kouluttaminen ei ole yksiselitteinen prosessi, varsinkaan kun on kyse tarvittavista tiedoista. Riippuu monesta asiasta:
- Mallin suunnittelu.
- Mitä työtä sen tarvitsee tehdä?
- Käyttämäsi tiedon tyyppi.
- Kuinka hyvin haluat sen toimivan?
LLM:ien koulutus vaatii kuitenkin yleensä valtavan määrän tekstidataa. Mutta kuinka massiivisesta me puhumme? No, ajattele paljon pidemmälle kuin gigatavuja (GB). Tarkastelemme yleensä teratavuja (TB) tai jopa petatavuja (PB).
Harkitse GPT-3:a, joka on yksi suurimmista LLM-yrityksistä. Sitä koulutetaan 570 Gt tekstidataa. Pienemmät LLM:t saattavat tarvita vähemmän – ehkä 10–20 Gt tai jopa 1 Gt gigatavua – mutta se on silti paljon.

Mutta kyse ei ole vain tietojen koosta. Myös laadulla on väliä. Tietojen on oltava puhtaita ja monipuolisia, jotta malli oppii tehokkaasti. Etkä myöskään voi unohtaa muita palapelin tärkeitä osia, kuten tarvitsemaasi laskentatehoa, harjoittelussa käyttämiäsi algoritmeja ja laitteistoasennuksia. Kaikilla näillä tekijöillä on suuri merkitys LLM:n koulutuksessa.
Suurten kielimallien nousu: miksi niillä on merkitystä
LLM:t eivät ole enää vain käsite tai kokeilu. Heillä on yhä tärkeämpi rooli digitaalisessa ympäristössämme. Mutta miksi näin tapahtuu? Mikä tekee näistä LLM:istä niin tärkeitä? Tarkastellaanpa joitain keskeisiä tekijöitä.
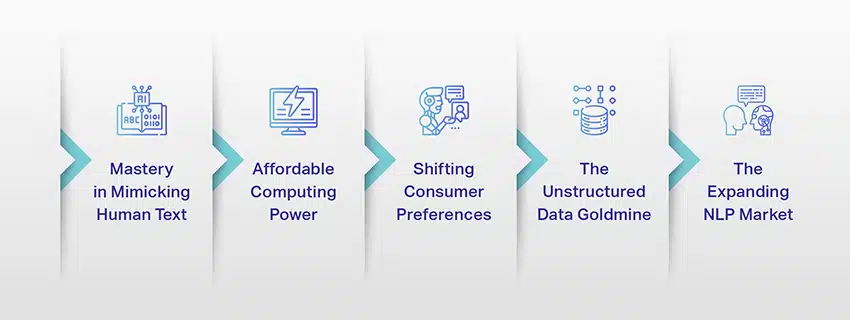
Mestarillinen ihmistekstin matkiminen
LLM:t ovat muuttaneet tapaamme käsitellä kielipohjaisia tehtäviä. Nämä mallit on rakennettu tukevilla koneoppimisalgoritmeilla, ja niissä on kyky ymmärtää ihmisen kielen vivahteita, mukaan lukien konteksti, tunteet ja jossain määrin sarkasmi. Tämä kyky matkia ihmiskieltä ei ole pelkkä uutuus, sillä on merkittäviä seurauksia.
LLM:ien edistyneet tekstintuotantokyvyt voivat parantaa kaikkea sisällön luomisesta asiakaspalveluun.
Kuvittele, että voisit kysyä digitaaliselle avustajalle monimutkaisen kysymyksen ja saada vastauksen, joka ei ole vain järkevä, vaan myös johdonmukainen, relevantti ja keskustelun sävyinen. Sitä LLM:t mahdollistavat. Ne edistävät intuitiivisempaa ja kiinnostavampaa ihmisen ja koneen välistä vuorovaikutusta, rikastuttavat käyttökokemuksia ja demokratisoivat tiedonsaantia.
Edullista laskentatehoa
LLM:ien nousu ei olisi ollut mahdollista ilman rinnakkaista kehitystä tietojenkäsittelyn alalla. Tarkemmin sanottuna laskennallisten resurssien demokratisoinnilla on ollut merkittävä rooli LLM:ien kehityksessä ja käyttöönotossa.
Pilvipohjaiset alustat tarjoavat ennennäkemättömän pääsyn korkean suorituskyvyn laskentaresursseihin. Näin pienetkin organisaatiot ja riippumattomat tutkijat voivat kouluttaa kehittyneitä koneoppimismalleja.
Lisäksi prosessointiyksiköiden (kuten GPU:t ja TPU:t) parannukset yhdistettynä hajautetun laskennan lisääntymiseen ovat tehneet mahdolliseksi kouluttaa miljardeja parametreja sisältäviä malleja. Tämä lisääntynyt laskentatehon käytettävyys mahdollistaa LLM-yritysten kasvun ja menestyksen, mikä johtaa enemmän innovaatioihin ja sovelluksiin alalla.
Kuluttajien asetusten muuttaminen
Nykypäivän kuluttajat eivät vain halua vastauksia; he haluavat mukaansatempaavaa ja suhteellista vuorovaikutusta. Kun yhä useammat ihmiset kasvavat digitaalitekniikan parissa, on selvää, että tarve luonnollisemmalta ja inhimilliseltä tuntuvalle teknologialle kasvaa. LLM:t tarjoavat vertaansa vailla olevan mahdollisuuden täyttää nämä odotukset. Luomalla ihmisen kaltaista tekstiä nämä mallit voivat luoda kiinnostavia ja dynaamisia digitaalisia kokemuksia, jotka voivat lisätä käyttäjien tyytyväisyyttä ja uskollisuutta. Olipa kyseessä asiakaspalvelua tarjoavia tekoäly-chatbotteja tai uutispäivityksiä tarjoavia ääniassistentteja, LLM:t aloittavat tekoälyn aikakauden, joka ymmärtää meitä paremmin.
Strukturoimattoman datan kultakaivos
Strukturoimaton data, kuten sähköpostit, sosiaalisen median viestit ja asiakasarvostelut, on oivallusten aarreaitta. On arvioitu, että se on ohi 80% yritystiedoista on jäsentämätöntä ja se kasvaa nopeudella 55% vuodessa. Nämä tiedot ovat yrityksille kultakaivos, jos niitä käytetään oikein.
LLM:t tulevat esiin tässä, koska he pystyvät käsittelemään ja ymmärtämään tällaisia tietoja laajassa mittakaavassa. He pystyvät käsittelemään tehtäviä, kuten tunteiden analysointia, tekstin luokittelua, tiedon poiminta ja paljon muuta, mikä tarjoaa arvokkaita oivalluksia.
Olipa kyseessä trendien tunnistaminen sosiaalisen median viesteistä tai asiakkaiden mielipiteiden mittaamisesta arvostelujen perusteella, LLM:t auttavat yrityksiä navigoimaan suuressa määrässä jäsentelemätöntä dataa ja tekemään datalähtöisiä päätöksiä.
Laajentuvat NLP-markkinat
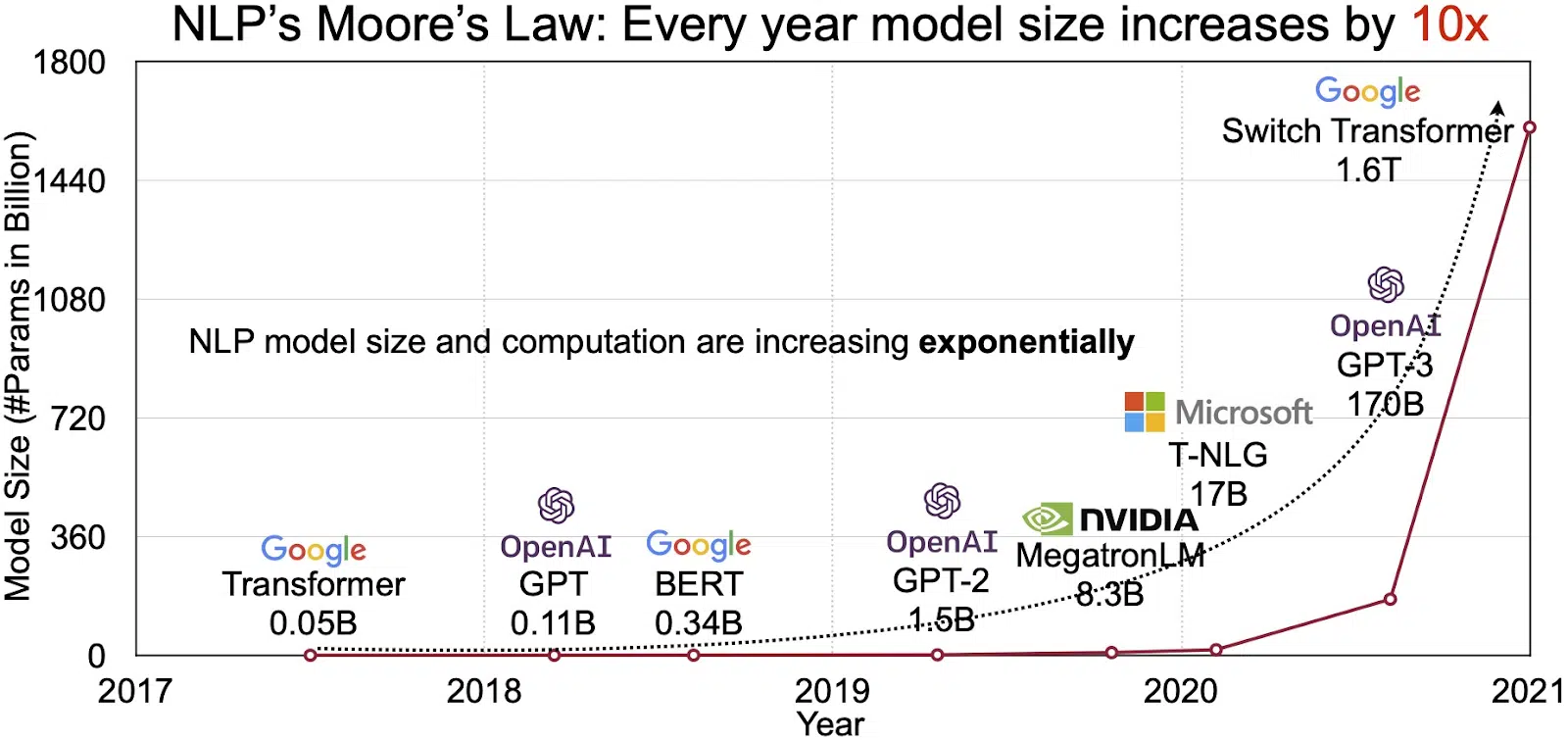
LLM:ien potentiaali heijastuu nopeasti kasvavilla luonnollisen kielenkäsittelyn (NLP) markkinoilla. Analyytikot ennustavat NLP-markkinoiden laajentuvan 11 miljardia dollaria vuonna 2020 yli 35 miljardiin dollariin vuoteen 2026 mennessä. Mutta se ei ole vain markkinoiden koko, joka laajenee. Myös itse mallit kasvavat sekä fyysisen koon että käsittelemien parametrien lukumäärän osalta. LLM-yritysten kehitys vuosien varrella, kuten alla olevasta kuvasta näkyy (kuvan lähde: linkki), korostaa niiden kasvavaa monimutkaisuutta ja kapasiteettia.
Suurten kielimallien suosittuja käyttötapauksia
Tässä on joitain LLM:n suosituimmista ja yleisimmistä käyttötapauksista:
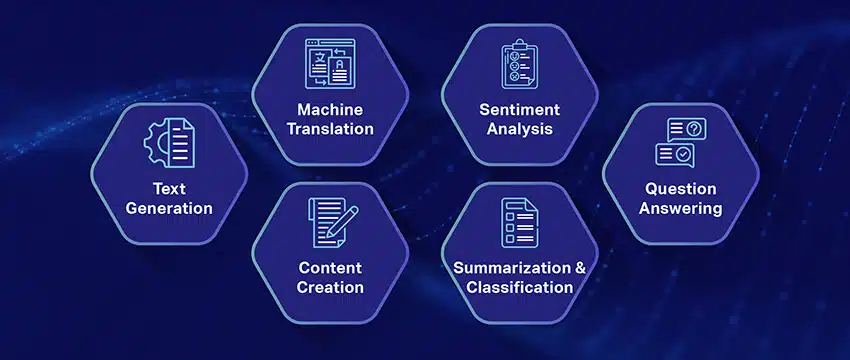
- Luonnollisen kielen tekstin luominen: Suuret kielimallit (LLM) yhdistävät tekoälyn ja laskennallisen lingvistiikan voiman tuottaakseen itsenäisesti tekstejä luonnollisella kielellä. Ne voivat vastata erilaisiin käyttäjien tarpeisiin, kuten kirjoittaa artikkeleita, luoda kappaleita tai käydä keskusteluja käyttäjien kanssa.
- Käännös koneilla: LLM:itä voidaan käyttää tehokkaasti kääntämään tekstiä minkä tahansa kieliparin välillä. Nämä mallit hyödyntävät syväoppimisalgoritmeja, kuten toistuvia hermoverkkoja, ymmärtääkseen sekä lähde- että kohdekielten kielellisen rakenteen, mikä helpottaa lähdetekstin kääntämistä halutulle kielelle.
- Alkuperäisen sisällön luominen: LLM:t ovat avanneet koneille mahdollisuuksia luoda yhtenäistä ja loogista sisältöä. Tätä sisältöä voidaan käyttää blogitekstien, artikkeleiden ja muun tyyppisen sisällön luomiseen. Mallit hyödyntävät syvällistä syvällistä oppimiskokemustaan muotoillakseen ja jäsentääkseen sisällön uudella tavalla ja käyttäjäystävällisellä tavalla.
- Analysoi tunteita: Yksi kiehtova Large Language Models -sovellus on tunneanalyysi. Tässä mallia koulutetaan tunnistamaan ja luokittelemaan selostetussa tekstissä esiintyviä tunnetiloja ja tunteita. Ohjelmisto voi tunnistaa tunteita, kuten positiivisuuden, negatiivisuuden, neutraalisuuden ja muita monimutkaisia tunteita. Tämä voi tarjota arvokasta tietoa asiakkaiden palautteesta ja näkemyksistä erilaisista tuotteista ja palveluista.
- Tekstin ymmärtäminen, yhteenveto ja luokittelu: LLM:t luovat tekoälyohjelmistolle toimivan rakenteen tekstin ja sen kontekstin tulkitsemiseen. Opastamalla mallia ymmärtämään ja tarkastelemaan valtavia tietomääriä, LLM:t mahdollistavat tekoälymallien ymmärtämisen, yhteenvedon ja jopa luokittelun erilaisissa muodoissa ja malleissa.
- Kysymyksiin vastaaminen: Suuret kielimallit varustavat Question Answering (QA) -järjestelmät kyvyllä havaita tarkasti käyttäjän luonnollisen kielen kyselyt ja vastata niihin. Suosittuja esimerkkejä tästä käyttötapauksesta ovat ChatGPT ja BERT, jotka tutkivat kyselyn kontekstia ja seulovat laajan tekstikokoelman antaakseen osuvia vastauksia käyttäjien kysymyksiin.

Osa-of-Speech (POS) merkitseminen
Lauseissa olevat sanat on merkitty niiden kielioppifunktiolla, kuten verbit, substantiivit, adjektiivit jne. Tämä prosessi auttaa mallia ymmärtämään kielioppia ja sanojen välisiä yhteyksiä.

Nimetyn kokonaisuuden tunnistus (NER)
Nimetyt entiteetit, kuten organisaatiot, sijainnit ja ihmiset lauseessa, on merkitty. Tämä harjoitus auttaa mallia tulkitsemaan sanojen ja lauseiden semanttisia merkityksiä ja antaa tarkempia vastauksia.

Aistien analyysi
Tekstidatalle on liitetty tunnetunnisteita, kuten positiivinen, neutraali tai negatiivinen, mikä auttaa mallia ymmärtämään lauseiden emotionaalisen pohjasävyn. Se on erityisen hyödyllinen vastattaessa kyselyihin, joihin liittyy tunteita ja mielipiteitä.
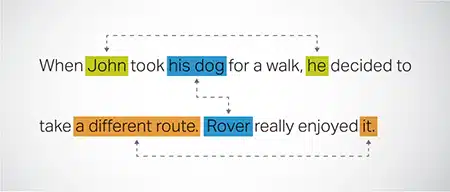
Coreference Resoluutio
Sellaisten tapausten tunnistaminen ja ratkaiseminen, joissa samaan kokonaisuuteen viitataan tekstin eri osissa. Tämä vaihe auttaa mallia ymmärtämään lauseen kontekstin, mikä johtaa johdonmukaisiin vastauksiin.
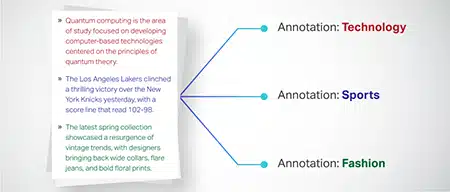
Tekstiluokitus
Tekstitiedot on luokiteltu ennalta määritettyihin ryhmiin, kuten tuotearvosteluihin tai uutisartikkeleihin. Tämä auttaa mallia tunnistamaan tekstin genren tai aiheen ja luo osuvampia vastauksia.
Shaipin tarjous
Shaip tarjoaa laajan valikoiman palveluita, jotka auttavat organisaatioita hallitsemaan, analysoimaan ja hyödyntämään tietojaan parhaalla mahdollisella tavalla.
Tietojen Web-kaappaus
Yksi Shaipin tarjoamista keskeisistä palveluista on tietojen kaavinta. Tämä tarkoittaa tietojen poimimista verkkotunnuskohtaisista URL-osoitteista. Hyödyntämällä automatisoituja työkaluja ja tekniikoita, Shaip voi nopeasti ja tehokkaasti kaapata suuria määriä tietoa eri verkkosivustoilta, tuoteoppaista, teknisestä dokumentaatiosta, verkkofoorumeilta, online-arvosteluista, asiakaspalvelutiedoista, alan sääntelyasiakirjoista jne. Tämä prosessi voi olla korvaamaton yrityksille, kun kerätä asiaankuuluvaa ja erityistä tietoa useista lähteistä.

Konekäännös
Kehitä malleja käyttämällä laajoja monikielisiä tietojoukkoja ja vastaavia transkriptioita tekstin kääntämiseksi eri kielille. Tämä prosessi auttaa purkamaan kielellisiä esteitä ja edistää tiedon saatavuutta.
Taksonomian erottaminen ja luominen
Shaip voi auttaa taksonomian poimimisessa ja luomisessa. Tämä edellyttää tietojen luokittelua ja luokittelua jäsenneltyyn muotoon, joka kuvastaa eri tietopisteiden välisiä suhteita. Tämä voi olla erityisen hyödyllistä yrityksille heidän tietojensa järjestämisessä, mikä tekee niistä helpommin saatavilla ja helpompia analysoida. Esimerkiksi verkkokaupassa tuotetiedot voidaan luokitella tuotetyypin, brändin, hinnan jne. perusteella, mikä helpottaa asiakkaiden navigointia tuoteluettelossa.
Tiedonkeruu
Tiedonkeruupalvelumme tarjoavat kriittistä reaalimaailman tai synteettistä dataa, jota tarvitaan luovien tekoälyalgoritmien kouluttamiseen ja malliesi tarkkuuden ja tehokkuuden parantamiseen. Tiedot ovat puolueettomia, eettisesti ja vastuullisesti hankittuja, samalla kun pidetään mielessä tietosuoja ja turvallisuus.

Kysymys & Vastaus
Kysymysvastaus (QA) on luonnollisen kielen prosessoinnin alakenttä, joka keskittyy kysymyksiin automaattiseen vastaamiseen ihmiskielellä. Laadunvarmistusjärjestelmät on koulutettu laajaan tekstiin ja koodiin, minkä ansiosta ne voivat käsitellä erilaisia kysymyksiä, mukaan lukien tosiasioihin, määritelmällisiin ja mielipiteisiin perustuvia kysymyksiä. Domain-osaaminen on ratkaisevan tärkeää kehitettäessä QA-malleja, jotka on räätälöity tietyille aloille, kuten asiakastukeen, terveydenhuoltoon tai toimitusketjuun. Kuitenkin generatiivisten laadunvarmistuslähestymistapojen avulla mallit voivat luoda tekstiä ilman verkkotuntia, tukeutuen pelkästään kontekstiin.
Asiantuntijatiimimme voi huolellisesti tutkia kattavia asiakirjoja tai oppaita luodakseen kysymys-vastaus-pareja, mikä helpottaa luovan tekoälyn luomista yrityksille. Tällä lähestymistavalla voidaan tehokkaasti käsitellä käyttäjien tiedusteluja louhimalla olennaista tietoa laajasta aineistosta. Sertifioidut asiantuntijamme varmistavat korkealaatuisten kysymys- ja vastausparien tuotannon, jotka kattavat eri aiheet ja alueet.

Tekstin yhteenveto
Asiantuntijamme pystyvät tislaamaan kattavia keskusteluja tai pitkiä dialogeja ja toimittamaan ytimekkäitä ja oivaltava yhteenvetoja laajasta tekstidatasta.

Tekstin luominen
Kouluta malleja käyttämällä laajaa tietojoukkoa tekstiä eri tyyleissä, kuten uutisartikkeleissa, kaunokirjallisuudessa ja runoissa. Nämä mallit voivat sitten tuottaa erityyppistä sisältöä, mukaan lukien uutiset, blogimerkinnät tai sosiaalisen median viestit, tarjoten kustannustehokkaan ja aikaa säästävän ratkaisun sisällön luomiseen.
Puheentunnistus
Kehitä puhutun kielen ymmärtämiseen kykeneviä malleja eri sovelluksiin. Tämä sisältää ääniaktivoidut avustajat, saneluohjelmistot ja reaaliaikaiset käännöstyökalut. Prosessi sisältää kattavan tietojoukon hyödyntämisen, joka koostuu puhutun kielen äänitallenteista ja niitä vastaavista transkriptioista.

Tuotesuositukset
Kehitä malleja käyttämällä laajoja tietojoukkoja asiakkaiden ostohistoriasta, mukaan lukien etiketit, jotka osoittavat tuotteet, joita asiakkaat ovat taipuvaisia ostamaan. Tavoitteena on tarjota asiakkaille tarkkoja ehdotuksia, mikä lisää myyntiä ja lisää asiakastyytyväisyyttä.
Kuvan tekstitys
Mullistaa kuvien tulkintaprosessisi huippumodernilla, tekoälypohjaisella kuvien tekstityspalvelullamme. Tuomme kuviin elinvoimaa tuottamalla tarkkoja ja kontekstuaalisesti merkityksellisiä kuvauksia. Tämä tasoittaa tietä yleisöllesi innovatiivisille sitoutumis- ja vuorovaikutusmahdollisuuksille visuaalisen sisältösi kanssa.

Tekstistä puheeksi -palveluiden koulutus
Tarjoamme laajan tietojoukon, joka koostuu ihmisen puheen äänitallenteista, jotka ovat ihanteellisia tekoälymallien koulutukseen. Nämä mallit pystyvät tuottamaan luonnollisia ja mukaansatempaavia ääniä sovelluksillesi, mikä tarjoaa käyttäjillesi erottuvan ja mukaansatempaavan äänikokemuksen.



