
Avain tekoälyn kehittämisen esteiden voittamiseen: luotettavampi data
Nykyään keskimääräisellä ihmisellä on nyt taskussa miljoonia kertoja enemmän laskentatehoa kuin NASA: n täytyi vetää kuun laskeutuminen vuonna 1969. Sama kaikkialla oleva laite, joka osoittaa kätevästi runsaasti laskentatehoa, täyttää myös toisen edellytyksen tekoälyn kultakaudelle: runsaasti tietoa. Tietojen ylikuormitustutkimusryhmän oivallusten mukaan 90% maailman tiedoista on luotu kahden viime vuoden aikana. Nyt, kun laskentatehon eksponentiaalinen kasvu on vihdoin lähentynyt yhtä meteoristiseen kasvuun datan tuottamisessa, tekoälydatainnovaatiot räjähtävät niin paljon, että joidenkin asiantuntijoiden mielestä käynnistetään neljäs teollinen vallankumous.
Kansallisen riskipääomayhdistyksen tiedot osoittavat, että tekoälysektorin investoinnit olivat ennätykselliset 6.9 miljardia dollaria vuoden 2020 ensimmäisellä neljänneksellä. Tekoälyn työkalujen potentiaalia ei ole vaikea nähdä, koska niitä hyödynnetään jo ympärillämme. Jotkut tekoälyn tuotteiden näkyvimmistä käyttötapauksista ovat suosikkisovelluksiemme, kuten Spotify ja Netflix, suosittelumoottorit. Vaikka on hauskaa löytää uusi taiteilija kuunneltavaksi tai uusi TV-ohjelma, jota katsella, nämä toteutukset ovat melko matalia. Muut algoritmit arvioivat testitulokset - osittain määrittämällä, missä opiskelijat hyväksytään korkeakouluun - ja toiset taas käyvät läpi ehdokkaiden ansioluettelot ja päättävät, mitkä hakijat saavat tietyn työpaikan. Joillakin tekoälytyökaluilla voi olla jopa elämän tai kuoleman vaikutuksia, kuten tekoälyn malli, joka seuloo rintasyöpää (joka ylittää lääkärit).
Huolimatta siitä, että sekä reaalimaailman esimerkit tekoälyn kehityksestä että uusien startup-yritysten joukosta, jotka pyrkivät luomaan uuden sukupolven muutostyökaluja, ovat kasvaneet tasaisesti, tehokkaan kehittämisen ja toteuttamisen haasteet ovat edelleen. Erityisesti tekoälyn lähtö on vain niin tarkka kuin syöttö sallii, mikä tarkoittaa, että laatu on tärkeintä.

Monimutkaisten vaatimusten noudattaminen vaatii
Ikään kuin laatutietojen löytäminen ei olisi ollut tarpeeksi vaikeaa, jotkut teollisuudenalat, jotka hyötyvät eniten tekoälytiedon innovaatioista, ovat myös eniten säänneltyjä. Terveydenhoito on ehkä paras esimerkki, ja vaikka HIT Infrastructure -yrityksen kyselyssä todettiin, että 91% alan sisäpiiriläisistä uskoo tekniikan parantavan hoidon saatavuutta, optimismia lieventää se tosiasia, että 75% pitää sitä uhkana potilaiden turvallisuudelle ja yksityisyydelle - ja potilaat eivät ole ainoita vaarassa.
Sairausvakuutuksen siirrettävyyttä ja vastuullisuutta koskevalla lailla annetut laaja-alaiset säädökset ovat nyt ristiriidassa useiden paikallisten tietojen noudattamisen esteiden kanssa, kuten Euroopan yleisen tietosuoja-asetuksen, Kalifornian kuluttajansuojalain Yhdysvalloissa ja Singaporen henkilötietosuojalain. Näihin paikallisiin säädöksiin liittyy monia muita, ja kun terveydenhuolto on merkittävämpi terveydenhuollon tietolähde, on todennäköistä, että säännökset saavat entistä tiukemman otteen potilaiden tiedoista kuljetuksen aikana. Tämän seurauksena Shaipin turvallinen ja yhteensopiva pilvialusta osoittautuu vieläkin arvokkaammaksi keinoksi kerätä ja käyttää terveydenhuollon tietoja tekoälyn tuotteiden kouluttamiseksi.
Henkilökohtaisesti tunnistettavissa olevat tiedot voivat olla merkittävä uhka tekoälykehityksellesi, mutta jopa täysin yhteensopiva toteutus on vaarassa, jos se ei pysty tuottamaan sellaisia tarkkoja tuloksia, joilla on vain erilaisia harjoittelutietoja. Journal of the American Medical Association -lehdessä vuonna 2020 tehty tutkimus osoitti, että koneoppimisalgoritmeja lääketieteessä koulutetaan useimmiten Kalifornian, New Yorkin ja Massachusettsin potilaiden tiedoilla. Ottaen huomioon, että nämä potilaat edustavat alle viidesosaa Yhdysvaltain väestöstä, sanomatta muusta maailmasta, on vaikea kuvitella, kuinka nämä mallit voisivat tuottaa muuta kuin puolueellisia tuloksia.

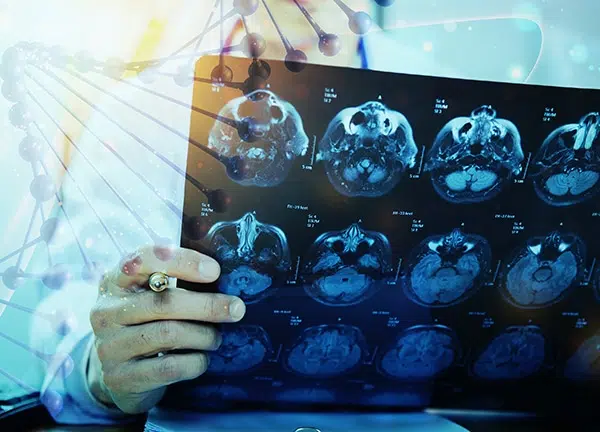 Shaip tunnistaa vaikeudet varmistaa vaatimustenmukaisten, maantieteellisesti erilaisten tietojen saaminen, ja Shaip tarjoaa lisensoituja terveydenhoitotietoja monilta eri alueilta, jotka on erityisesti kuratoitu tarkkojen algoritmien rakentamiseksi. Nämä tiedot ovat tekstin muodossa, kuten lääketieteellisiä asiakirjoja tai väitetietoja, lääketieteellistä diagnostista kuvantamista, kuten TT-skannauksia, ääntä, kuten lääkäreiden puhettuja muistiinpanoja tai lääkäreiden ja potilaiden välisiä keskusteluja, ja jopa videoita MRI-tuloksista. Se on myös täysin tunnistettu ja nimettömänä, ja se suojaa organisaatiotasi sekä eettisiltä että taloudellisilta vaikutuksilta, jotka voivat seurata rikkomusta missä tahansa kasvavassa määrässä säännöksiä, jotka koskevat sekä kotimaista että kansainvälistä alkuperää olevia tietoja.
Shaip tunnistaa vaikeudet varmistaa vaatimustenmukaisten, maantieteellisesti erilaisten tietojen saaminen, ja Shaip tarjoaa lisensoituja terveydenhoitotietoja monilta eri alueilta, jotka on erityisesti kuratoitu tarkkojen algoritmien rakentamiseksi. Nämä tiedot ovat tekstin muodossa, kuten lääketieteellisiä asiakirjoja tai väitetietoja, lääketieteellistä diagnostista kuvantamista, kuten TT-skannauksia, ääntä, kuten lääkäreiden puhettuja muistiinpanoja tai lääkäreiden ja potilaiden välisiä keskusteluja, ja jopa videoita MRI-tuloksista. Se on myös täysin tunnistettu ja nimettömänä, ja se suojaa organisaatiotasi sekä eettisiltä että taloudellisilta vaikutuksilta, jotka voivat seurata rikkomusta missä tahansa kasvavassa määrässä säännöksiä, jotka koskevat sekä kotimaista että kansainvälistä alkuperää olevia tietoja.
Tekoälyn kehittämisen esteiden voittaminen
Tekoälyn kehittämistoimet sisältävät merkittäviä esteitä riippumatta siitä, missä teollisuudessa ne toimivat, ja prosessi, jossa siirrytään toteutettavasta ideasta menestyvään tuotteeseen, on vaikeuksia. Oikeiden tietojen hankkimisen haasteiden ja tarpeen anonymisoida tarpeen kaikkien asiaankuuluvien säännösten noudattamiseksi voi tuntua siltä, että algoritmin rakentaminen ja kouluttaminen on helppoa.
Jos haluat antaa organisaatiollesi kaikki tarvittavat edut uraauurtavan uuden tekoälykehityksen suunnittelussa, sinun kannattaa harkita kumppanuutta Shaipin kaltaisen yrityksen kanssa. Chetan Parikh ja Vatsal Ghiya perustivat Shaipin auttaakseen yrityksiä suunnittelemaan erilaisia ratkaisuja, jotka voivat muuttaa terveydenhuoltoa Yhdysvalloissa. Yli 16 vuoden liiketoiminnan jälkeen yrityksemme on kasvanut yli 600 tiimin jäseneksi, ja olemme työskennelleet satojen asiakkaita tekemään pakottavia ideoita tekoälyratkaisuiksi.
Kun organisaatiossasi työskentelevät henkilöt, prosessit ja alusta työskentelevät, voit heti avata seuraavat neljä etua ja tehdä projektistasi menestyksekkään lopputuloksen:
1. Kyky vapauttaa datatieteilijät
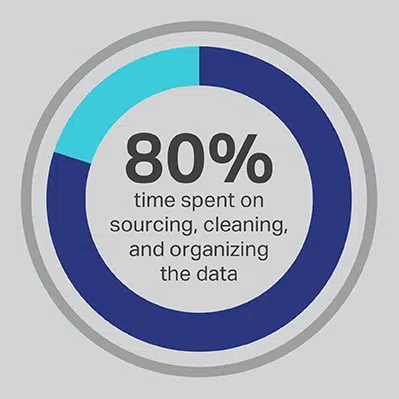
On selvää, että tekoälyn kehittämisprosessi vie paljon aikaa, mutta voit aina optimoida toiminnot, jotka tiimisi käyttää eniten aikaa. Palkkasit tietotutkijasi, koska he ovat asiantuntijoita kehittyneiden algoritmien ja koneoppimismallien kehittämisessä, mutta tutkimus osoittaa johdonmukaisesti, että nämä työntekijät käyttävät itse asiassa 80% ajastaan hankiessaan, siivoavat ja organisoineet hankkeen tehostavat tiedot. Yli kolme neljäsosaa (76%) datatieteilijöistä ilmoittaa, että nämä arkipäiväiset tiedonkeruuprosessit sattuvat olemaan heidän vähiten suosikki työpaikkansa, mutta laadukkaiden tietojen tarve jättää vain 20% ajastaan todelliseen kehitykseen. mielenkiintoisin ja älyllisesti stimuloiva teos monille datatieteilijöille. Hankkimalla tietoja kolmannen osapuolen toimittajan, kuten Shaipin kautta, yritys voi antaa kalliiden ja lahjakkaiden data-insinööriensä ulkoistaa työnsä datanvartijoina ja käyttää sen sijaan aikaansa tekoälyratkaisuihin, joissa ne voivat tuottaa eniten arvoa.
2. Kyky saavuttaa parempia tuloksia
 Monet tekoälyn kehityspäälliköt päättävät käyttää avoimen lähdekoodin tai väkijoukon tietoja vähentääkseen kuluja, mutta tämä päätös maksaa melkein aina enemmän pitkällä aikavälillä. Tämäntyyppiset tiedot ovat helposti saatavilla, mutta ne eivät voi vastata huolellisesti kuratoitujen tietojoukkojen laatua. Varsinkin väkijoukkolähtöisissä tiedoissa on virheitä, puutteita ja epätarkkuuksia, ja vaikka nämä ongelmat voidaan toisinaan ratkaista kehitysprosessin aikana insinöörien tarkalla silmällä, se vie lisää iteraatioita, joita ei tarvita, jos aloitat korkeammalla -laatutiedot alusta alkaen.
Monet tekoälyn kehityspäälliköt päättävät käyttää avoimen lähdekoodin tai väkijoukon tietoja vähentääkseen kuluja, mutta tämä päätös maksaa melkein aina enemmän pitkällä aikavälillä. Tämäntyyppiset tiedot ovat helposti saatavilla, mutta ne eivät voi vastata huolellisesti kuratoitujen tietojoukkojen laatua. Varsinkin väkijoukkolähtöisissä tiedoissa on virheitä, puutteita ja epätarkkuuksia, ja vaikka nämä ongelmat voidaan toisinaan ratkaista kehitysprosessin aikana insinöörien tarkalla silmällä, se vie lisää iteraatioita, joita ei tarvita, jos aloitat korkeammalla -laatutiedot alusta alkaen.
Luotettavuus avoimen lähdekoodin tietoihin on toinen yleinen pikakuvake, johon sisältyy omat karhut. Eriyttämisen puute on yksi suurimmista ongelmista, koska avoimen lähdekoodin datalla koulutettu algoritmi on helpompi kopioida kuin lisensoiduille tietojoukoille rakennettu. Menemällä tällä reitillä kutsut kilpailua avaruudessa olevista muista tulokkaista, jotka voivat alittaa hinnat ja ottaa markkinaosuuden milloin tahansa. Kun luotat Shaipiin, pääset käyttämään korkealaatuista tietoa, jonka taitava hallittu työvoima on koonnut, ja voimme myöntää sinulle yksinoikeuden lisenssin mukautettua tietojoukkoa varten, joka estää kilpailijoita luomasta helposti hankittua henkistä omaisuuttasi.
3. Pääsy kokeneille ammattilaisille
 Vaikka talosi luettelossa on ammattitaitoisia insinöörejä ja lahjakkaita datatieteilijöitä, tekoälytyökalut voivat hyötyä viisaudesta, joka tulee vain kokemuksen kautta. Aiheasiantuntijamme ovat johtaneet lukuisia tekoälyn toteutuksia alallaan ja oppineet arvokkaita opetuksia matkan varrella, ja heidän ainoana tavoitteena on auttaa sinua saavuttamaan omasi.
Vaikka talosi luettelossa on ammattitaitoisia insinöörejä ja lahjakkaita datatieteilijöitä, tekoälytyökalut voivat hyötyä viisaudesta, joka tulee vain kokemuksen kautta. Aiheasiantuntijamme ovat johtaneet lukuisia tekoälyn toteutuksia alallaan ja oppineet arvokkaita opetuksia matkan varrella, ja heidän ainoana tavoitteena on auttaa sinua saavuttamaan omasi.
Kun verkkotunnuksen asiantuntijat tunnistavat, järjestävät, luokittelevat ja merkitsevät tietoja sinulle, tiedät, että algoritmin kouluttamiseen käytetyt tiedot voivat tuottaa parhaat mahdolliset tulokset. Suoritamme myös säännöllistä laadunvarmistusta varmistaaksemme, että data on korkeimpien standardien mukaista ja toimii tarkoitetulla tavalla paitsi laboratoriossa myös tosielämän tilanteissa.
4. Nopeutettu kehityksen aikajana
Tekoälyn kehitys ei tapahdu yhdessä yössä, mutta se voi tapahtua nopeammin, kun kumppanit Shaipin kanssa. Sisäinen tiedonkeruu ja merkinnät luovat merkittävän operatiivisen pullonkaulan, joka pitää kiinni muusta kehitysprosessista. Shaipin kanssa työskenteleminen antaa sinulle välittömän pääsyn laajaan käyttövalmiiden tietojen kirjastoon, ja asiantuntijamme pystyvät hankkimaan kaiken tarvitsemasi lisäpanokset teollisuuden syvällisen tietämyksemme ja globaalin verkostomme avulla. Tiimisi voi ryhtyä heti työskentelemään todellisen kehityksen parissa ilman hankinnan ja merkintöjen taakkaa, ja koulutusmallimme voi auttaa tunnistamaan varhaiset epätarkkuudet vähentämään tarkkuustavoitteiden saavuttamiseksi tarvittavia iteraatioita.
Jos et ole valmis ulkoistamaan kaikkia tiedonhallinnan näkökohtia, Shaip tarjoaa myös pilvipohjaisen alustan, joka auttaa tiimejä tuottamaan, muuttamaan ja merkitsemään tehokkaammin erityyppisiä tietoja, mukaan lukien kuvan, videon, tekstin ja äänen tuki . ShaipCloud sisältää useita intuitiivisia vahvistus- ja työnkulkutyökaluja, kuten patentoidun ratkaisun kuormituksen seuraamiseen ja seuraamiseen, transkriptiotyökalun monimutkaisten ja vaikeiden äänitallenteiden transkriptioon sekä laadunvalvontakomponentin tinkimättömän laadun varmistamiseksi. Mikä parasta, se on skaalautuva, joten se voi kasvaa projektisi erilaisten vaatimusten kasvaessa.
Tekoälyn innovaatioiden aika on vasta alkamassa, ja näemme tulevina vuosina uskomattomia edistysaskeleita ja innovaatioita, joilla on mahdollisuus muuttaa kokonaisia teollisuudenaloja tai jopa muuttaa koko yhteiskuntaa. Shaipissa haluamme käyttää asiantuntemustamme palvelemaan muuttuvana voimana, joka auttaa maailman vallankumouksellisimpia yrityksiä hyödyntämään tekoälyratkaisujen voimaa kunnianhimoisten tavoitteiden saavuttamiseksi.
Meillä on syvällinen kokemus terveydenhuollon sovelluksista ja keskustelutaidoista, mutta meillä on myös tarvittavat taidot mallien kouluttamiseen melkein mihin tahansa sovellukseen. Jos haluat lisätietoja siitä, kuinka Shaip voi auttaa viedä projektisi ideasta toteutukseen, tutustu verkkosivustollamme oleviin moniin resursseihin tai ota meihin yhteyttä tänään.
