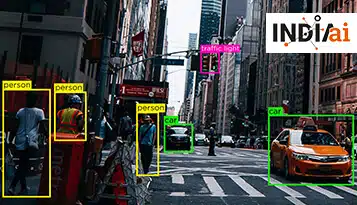
Nimetty entiteettitunnistus (NER) on luonnollisen kielen käsittelyn (NLP) keskeinen osa, joka auttaa tunnistamaan ja luokittelemaan tiettyjä yksityiskohtia suurissa tekstimäärissä. NER-sovelluksia ovat muun muassa tiedon poimiminen, tekstin yhteenveto ja tunteiden analysointi. Tehokas NER edellyttää erilaisia tietojoukkoja koneoppimismallien kouluttamiseen.
Viisi merkittävää avoimen lähdekoodin tietojoukkoa NER:lle ovat:
- CONLL 2003: Uutisten verkkotunnus
- CADEC: Lääketieteellinen verkkotunnus
- WikiNEuRal: Wikipedian verkkotunnus
- OntoNotes 5: Erilaisia verkkotunnuksia
- BBN: Erilaisia verkkotunnuksia
Näiden tietojoukkojen etuja ovat:
- saavutettavuus: Ne ovat ilmaisia ja kannustavat yhteistyöhön
- Tietojen rikkaus: Ne sisältävät monipuolista dataa, mikä parantaa mallin suorituskykyä
- Yhteisön tuki: Heillä on usein tukeva käyttäjäyhteisö
- Helpota tutkimusta: Erityisen hyödyllinen tutkijoille, joilla on rajalliset tiedonkeruuresurssit
Niissä on kuitenkin myös haittoja:
- Tietojen laatu: Ne voivat sisältää virheitä tai vääristymiä
- Spesifisyyden puute: Ne eivät välttämättä sovellu tiettyjä tietoja vaativiin tehtäviin
- Turvallisuus- ja tietosuojaongelmat: Arkaluonteisiin tietoihin liittyvät riskit
- Huolto: He eivät välttämättä saa säännöllisesti päivityksiä
Mahdollisista haitoista huolimatta avoimen lähdekoodin tietojoukoilla on olennainen rooli NLP:n ja koneoppimisen edistämisessä, erityisesti nimettyjen entiteettien tunnistamisen alalla.
Lue koko artikkeli:
https://wikicatch.com/open-datasets-for-named-entity-recognition/