
Vankka tekoälypohjainen ratkaisu perustuu tietoihin – ei vain mihin tahansa dataan, vaan korkealaatuiseen, tarkasti merkittyyn dataan. Vain paras ja hienostunein data voi toimia tekoälyprojektissasi, ja tällä tiedon puhtaudella on valtava vaikutus projektin lopputulokseen.
Olemme usein kutsuneet dataa tekoälyprojektien polttoaineeksi, mutta mikä tahansa data ei kelpaa. Jos tarvitset rakettipolttoainetta auttamaan projektiasi saavuttamaan nousun, et voi laittaa raakaöljyä säiliöön. Sen sijaan dataa (kuten polttoainetta) on tarkennettava huolellisesti, jotta varmistetaan, että vain laadukkain tieto toimii projektissasi. Tätä tarkennusprosessia kutsutaan datan annotaatioksi, ja siitä on olemassa useita pysyviä väärinkäsityksiä.
Määritä harjoitustietojen laatu huomautuksessa
Tiedämme, että tiedon laadulla on suuri merkitys tekoälyprojektin lopputulokseen. Jotkut parhaista ja tehokkaimmista ML-malleista ovat perustuneet yksityiskohtaisiin ja tarkasti merkittyihin tietokokonaisuuksiin.
Mutta kuinka tarkalleen määritämme merkinnän laadun?
Kun puhumme tietojen merkintä laatu, tarkkuus, luotettavuus ja johdonmukaisuus ovat tärkeitä. Tietojoukon sanotaan olevan tarkka, jos se vastaa perustotuutta ja todellista tietoa.
Tietojen johdonmukaisuus viittaa koko tietojoukon ylläpidettyyn tarkkuustasoon. Tietojoukon laatu määräytyy kuitenkin tarkemmin projektin tyypin, sen ainutlaatuisten vaatimusten ja halutun tuloksen perusteella. Siksi tämän pitäisi olla kriteerinä tietojen merkintöjen ja huomautusten laadun määrittämisessä.
Miksi tiedon laadun määrittäminen on tärkeää?
Tietojen laadun määritteleminen on tärkeää, sillä se toimii kokonaisvaltaisena tekijänä, joka määrittää projektin laadun ja tuloksen.
- Huonolaatuinen data voi vaikuttaa tuotteeseen ja liiketoimintastrategioihin.
- Koneoppimisjärjestelmä on yhtä hyvä kuin sen datan laatu, johon se on koulutettu.
- Laadukkaat tiedot eliminoivat uudelleentyöskentelyn ja siihen liittyvät kustannukset.
- Se auttaa yrityksiä tekemään tietoon perustuvia hankepäätöksiä ja noudattamaan säädöstenmukaisuutta.
Kuinka mittaamme koulutustietojen laatua merkitsemisen aikana?

Harjoitteludatan laadun mittaamiseen on useita menetelmiä, ja useimmat niistä alkavat luomalla ensin konkreettinen datamerkintäohje. Joitakin menetelmiä ovat:
Asiantuntijoiden määrittämät vertailuarvot
Laatukriteerit tai kultainen standardi huomautus menetelmät ovat helpoimpia ja edullisimpia laadunvarmistusvaihtoehtoja, jotka toimivat vertailukohtana projektin tuotoksen laatua mittaamaan. Se mittaa datamerkintöjä asiantuntijoiden määrittämää vertailuarvoa vasten.
Cronbachin alfa-testi
Cronbachin alfatesti määrittää tietojoukon kohteiden välisen korrelaation tai johdonmukaisuuden. Merkin luotettavuus ja suurempi tarkkuus voidaan mitata tutkimuksen perusteella.
Konsensusmittaus
Konsensusmittaus määrittää yksimielisyyden tason koneen tai ihmisen annotaattorien välillä. Yhteisymmärrykseen tulisi yleensä päästä jokaisesta kohdasta, ja se tulee ratkaista erimielisyyksien sattuessa.
Paneeliarvostelu
Asiantuntijapaneeli määrittää tarran tarkkuuden yleensä tarkastelemalla tietolappuja. Joskus tietty osa tietotarroista otetaan yleensä näytteeksi tarkkuuden määrittämiseksi.
Tarkastelu Harjoittelutiedot Laatu
Tekoälyprojekteihin osallistuvat yritykset ovat täysin automatisoituja, minkä vuoksi monet uskovat edelleen, että tekoälyn ohjaama automaattinen huomautus on nopeampi ja tarkempi kuin manuaalinen. Toistaiseksi todellisuus on se, että tietojen tunnistaminen ja luokittelu vaatii ihmisiä, koska tarkkuus on niin tärkeää. Automaattisen merkinnän kautta syntyvät lisävirheet vaativat lisätoistoja algoritmin tarkkuuden parantamiseksi, mikä säästää aikaa.
Toinen väärinkäsitys - ja joka todennäköisesti edistää automaattisen merkinnän käyttöönottoa - on, että pienillä virheillä ei ole paljon vaikutusta tuloksiin. Pienimmätkin virheet voivat tuottaa merkittäviä epätarkkuuksia AI-drift -nimisen ilmiön takia, jossa syötetietojen epäjohdonmukaisuudet johtavat algoritmin suuntaan, jota ohjelmoijat eivät koskaan tarkoittaneet.
Koulutusdatan laatua – tarkkuuden ja johdonmukaisuuden näkökohtia – tarkistetaan johdonmukaisesti vastaamaan projektien ainutlaatuisia vaatimuksia. Harjoitustietojen tarkastelu suoritetaan yleensä kahdella eri menetelmällä –
Automaattisesti merkittyjä tekniikoita
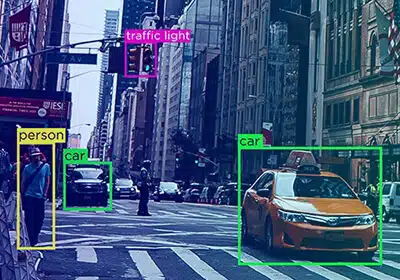 Automaattinen merkintöjen tarkistusprosessi varmistaa, että palaute ohjataan takaisin järjestelmään ja estää virheitä, jotta merkinnät voivat parantaa prosessejaan.
Automaattinen merkintöjen tarkistusprosessi varmistaa, että palaute ohjataan takaisin järjestelmään ja estää virheitä, jotta merkinnät voivat parantaa prosessejaan.
Tekoälyn ohjaama automaattinen merkintä on tarkkaa ja nopeampaa. Automaattinen merkintä vähentää manuaalisten laadunvarmistusten tarkistamiseen kuluvaa aikaa, jolloin he voivat käyttää enemmän aikaa tietojoukon monimutkaisiin ja kriittisiin virheisiin. Automaattinen merkintä voi myös auttaa havaitsemaan virheelliset vastaukset, toistot ja virheelliset merkinnät.
Manuaalisesti datatieteen asiantuntijoiden kautta
Datatieteilijät tarkistavat myös tietojen merkinnät varmistaakseen tietojoukon tarkkuuden ja luotettavuuden.
Pienet virheet ja huomautusten epätarkkuudet voivat vaikuttaa merkittävästi projektin lopputulokseen. Automaattisten merkintöjen tarkistustyökalut eivät välttämättä havaitse näitä virheitä. Datatieteilijät tekevät näytelaatutestauksia eri erikokoisista eristä havaitakseen tietojen epäjohdonmukaisuudet ja tahattomat virheet tietojoukossa.
Jokaisen tekoälyn otsikon takana on merkintäprosessi, ja Shaip voi auttaa tekemään siitä kivuttoman
AI-projektin sudenkuoppien välttäminen
Monia organisaatioita vaivaa sisäisten huomautusresurssien puute. Tietotieteilijöille ja insinööreille on suuri kysyntä, ja näiden ammattilaisten riittävä palkkaaminen tekoälyprojektiin tarkoittaa shekin kirjoittamista, joka on useimpien yritysten ulottumattomissa. Sen sijaan, että valitsisit budjettivaihtoehdon (kuten joukkolähdemerkinnän), joka lopulta palaa kummittelemaan sinua, harkitse merkintöjen ulkoistamista kokeneelle ulkoiselle kumppanille. Ulkoistaminen varmistaa korkean tarkkuuden ja vähentää samalla rekrytoinnin, koulutuksen ja johtamisen pullonkauloja, joita syntyy, kun yrität koota omaa tiimiä.
Kun ulkoistat huomautustarpeesi erityisesti Shaipin avulla, käytät voimakasta voimaa, joka voi nopeuttaa tekoälyaloitteesi ilman pikakuvakkeita, jotka vaarantavat kaikki tärkeät tulokset. Tarjoamme täysin hallittua työvoimaa, mikä tarkoittaa, että saat paljon suuremman tarkkuuden kuin mitä voisit saavuttaa joukkoliikenteen merkintöjen avulla. Alustava investointi voi olla suurempi, mutta se maksaa tuotekehitysprosessin aikana, kun halutun tuloksen saavuttamiseksi tarvitaan vähemmän iterointeja.
Datapalvelumme kattavat myös koko prosessin, mukaan lukien hankinta, jota useimmat muut merkintätarjoajat eivät voi tarjota. Kokemuksemme avulla voit nopeasti ja helposti hankkia suuria määriä korkealaatuisia, maantieteellisesti erilaisia tietoja, jotka on tunnistettu ja joka on kaikkien asiaankuuluvien määräysten mukainen. Kun tallennat nämä tiedot pilvipohjaiseen alustallemme, saat myös pääsyn todistettuihin työkaluihin ja työnkulkuihin, jotka parantavat projektisi yleistä tehokkuutta ja auttavat sinua edistymään nopeammin kuin luulit mahdolliseksi.
Ja lopuksi, meidän yrityksen sisäiset asiantuntijat ymmärtää ainutlaatuisia tarpeitasi. Olitpa rakentamassa chatbotia tai työskennellessäsi kasvojentunnistustekniikan parantamiseksi terveydenhuollon parantamiseksi, olemme olleet paikalla ja voimme auttaa kehittämään ohjeita, jotka varmistavat, että merkintäprosessi saavuttaa projektillesi määritellyt tavoitteet.
Shaipissa emme ole vain innoissaan tekoälyn uudesta aikakaudesta. Autamme sitä uskomattomilla tavoilla, ja kokemuksemme ovat auttaneet meitä saamaan lukemattomia onnistuneita projekteja kentältä. Ota yhteyttä meihin saadaksesi selville, mitä voimme tehdä omalle toteutuksellesi pyytää demoa tänään.


