
Tekoäly ja Big Data voivat löytää ratkaisuja globaaleihin ongelmiin samalla kun priorisoivat paikalliset ongelmat ja muuttavat maailmaa monin perustein. Tekoäly tuo ratkaisuja kaikille – ja kaikissa olosuhteissa, kodeista työpaikkoihin. AI-tietokoneet, joissa Koneen oppiminen koulutusta, voi simuloida älykästä käyttäytymistä ja keskusteluja automatisoidulla mutta yksilöllisellä tavalla.
Silti tekoälyllä on inkluusioongelma ja se on usein puolueellinen. Onneksi keskittyminen tekoälyn etiikka voi tuoda uusia mahdollisuuksia monipuolistamisen ja osallisuuden suhteen poistamalla tiedostamaton harha erilaisten koulutustietojen avulla.
Monimuotoisuuden merkitys tekoälyn harjoitusdatassa
 Harjoitteludatan monimuotoisuus ja laatu liittyvät toisiinsa, sillä toinen vaikuttaa toiseen ja vaikuttaa tekoälyratkaisun lopputulokseen. AI-ratkaisun menestys riippuu monipuolista dataa sitä koulutetaan. Tietojen monimuotoisuus estää tekoälyä sopeutumasta liikaa – eli malli toimii vain harjoitteluun käytetystä tiedosta tai oppii niistä. Ylisovituksella tekoälymalli ei voi tuottaa tuloksia, kun sitä testataan datalla, jota ei käytetä koulutuksessa.
Harjoitteludatan monimuotoisuus ja laatu liittyvät toisiinsa, sillä toinen vaikuttaa toiseen ja vaikuttaa tekoälyratkaisun lopputulokseen. AI-ratkaisun menestys riippuu monipuolista dataa sitä koulutetaan. Tietojen monimuotoisuus estää tekoälyä sopeutumasta liikaa – eli malli toimii vain harjoitteluun käytetystä tiedosta tai oppii niistä. Ylisovituksella tekoälymalli ei voi tuottaa tuloksia, kun sitä testataan datalla, jota ei käytetä koulutuksessa.
Tekoälykoulutuksen nykytila tiedot
Tietojen epätasa-arvo tai monimuotoisuuden puute johtaisi epäreiluihin, epäeettisiin ja ei-kattavaisiin tekoälyratkaisuihin, jotka voisivat syventää syrjintää. Mutta miten ja miksi datan monimuotoisuus liittyy tekoälyratkaisuihin?
Kaikkien luokkien epätasainen edustus johtaa kasvojen virheelliseen tunnistamiseen – yksi tärkeä tapaus on Google Photos, joka luokitteli mustan parin "gorillaksi". Ja Meta kehottaa käyttäjää katsomaan videota mustista miehistä, haluaako käyttäjä "jatkaa kädellisten videoiden katselua".
Esimerkiksi etnisten tai rodullisten vähemmistöjen epätarkka tai virheellinen luokittelu, erityisesti chatboteissa, voi johtaa ennakkoluuloihin tekoälyn koulutusjärjestelmissä. Vuoden 2019 raportin mukaan Syrjivät järjestelmät – sukupuoli, rotu, voima tekoälyssä, yli 80 % tekoälyn opettajista on miehiä; Naisten tekoälytutkijat FB:ssä muodostavat vain 15 % ja 10 % Googlessa.
Erilaisten koulutustietojen vaikutus tekoälyn suorituskykyyn
 Tiettyjen ryhmien ja yhteisöjen jättäminen pois tietojen esittämisestä voi johtaa vääristyneisiin algoritmeihin.
Tiettyjen ryhmien ja yhteisöjen jättäminen pois tietojen esittämisestä voi johtaa vääristyneisiin algoritmeihin.
Tietojen harhaa tuodaan usein vahingossa tietojärjestelmiin – alinäytteenotolla tiettyjä rotuja tai ryhmiä. Kun kasvojentunnistusjärjestelmiä koulutetaan erilaisille kasvoille, se auttaa mallia tunnistamaan erityispiirteet, kuten kasvoelinten sijainnin ja värivaihtelut.
Toinen tulos epätasapainoisesta tarrojen taajuudesta on, että järjestelmä saattaa pitää vähemmistönä poikkeavana, kun se painetaan tuottamaan tuloste lyhyessä ajassa.
Monimuotoisuuden saavuttaminen AI-koulutusdatassa
Toisaalta monipuolisen tietojoukon luominen on myös haaste. Tiettyjä luokkia koskevien tietojen puute voi johtaa aliedustukseen. Sitä voidaan lieventää tekemällä tekoälyn kehittäjäryhmistä monipuolisempia taitojen, etnisen alkuperän, rodun, sukupuolen, kurinalaisuuden ja muiden suhteen. Lisäksi ihanteellinen tapa käsitellä tekoälyn tiedon monimuotoisuusongelmia on kohdata se alusta alkaen sen sijaan, että yritetään korjata tehtyjä asioita – lisäämällä monimuotoisuutta tiedonkeruu- ja kuratointivaiheessa.
Tekoälystä huolimatta se riippuu edelleen ihmisten keräämistä, valitsemista ja kouluttamista tiedoista. Ihmisten luontainen harha heijastuu heidän keräämiinsä tietoihin, ja tämä tiedostamaton harha hiipii myös ML-malleihin.
Vaiheet erilaisten harjoitustietojen keräämiseen ja kuratointiin
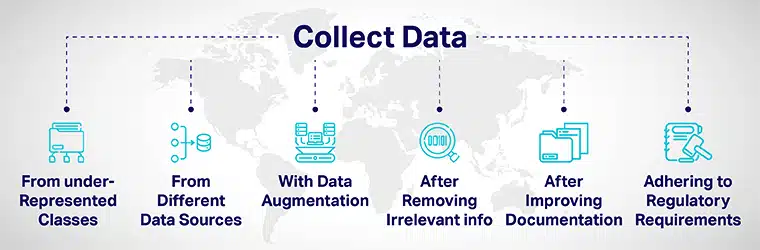
Tietojen monimuotoisuus voidaan saavuttaa:
- Lisää harkitusti enemmän tietoja aliedustetuista luokista ja paljasta mallisi erilaisille datapisteille.
- Keräämällä tietoa eri tietolähteistä.
- Lisäämällä tietoja tai manipuloimalla keinotekoisesti tietojoukkoja lisäämällä/sisällyttämällä uusia tietopisteitä, jotka eroavat selvästi alkuperäisistä tietopisteistä.
- Kun palkkaat hakijoita tekoälyn kehitysprosessiin, poista hakemuksesta kaikki työn kannalta merkityksettömät tiedot.
- Avoimuuden ja vastuullisuuden lisääminen parantamalla mallien kehittämisen ja arvioinnin dokumentointia.
- Otetaan käyttöön säännöksiä monimuotoisuuden rakentamiseksi ja inklusiivisuus tekoälyssä järjestelmät ruohonjuuritasolta. Useat hallitukset ovat kehittäneet ohjeita, joilla varmistetaan monimuotoisuus ja lievennetään tekoälyn harhaa, joka voi tuottaa epäoikeudenmukaisia tuloksia.
[Lue myös: Lue lisää AI Training -tiedonkeruuprosessista ]
Yhteenveto
Tällä hetkellä vain harvat suuret teknologiayritykset ja oppimiskeskukset ovat yksinomaan mukana kehittämässä tekoälyratkaisuja. Nämä eliittitilat ovat täynnä syrjäytymistä, syrjintää ja ennakkoluuloja. Nämä ovat kuitenkin tiloja, joissa tekoälyä kehitetään, ja näiden kehittyneiden tekoälyjärjestelmien taustalla oleva logiikka on täynnä samaa harhaa, syrjintää ja poissulkemista, joita aliedustetut ryhmät kantavat.
Monimuotoisuudesta ja syrjimättömyydestä puhuttaessa on tärkeää kyseenalaistaa ihmiset, joita se hyödyttää ja joita se vahingoittaa. Meidän pitäisi myös tarkastella, ketä se asettaa epäedulliseen asemaan – pakottamalla ajatuksen "normaalista" ihmisestä tekoäly saattaa vaarantaa "muut".
Tekoälytietojen monimuotoisuudesta keskusteleminen valtasuhteiden, tasa-arvon ja oikeudenmukaisuuden tunnustamatta ei näytä suurempaa kuvaa. Ymmärtääksemme täysin tekoälyn koulutusdatan moninaisuuden laajuuden ja kuinka ihmiset ja tekoäly voivat yhdessä lieventää tätä kriisiä, ota yhteyttä Shaipin insinööreihin. Meillä on erilaisia tekoälyinsinöörejä, jotka voivat tarjota dynaamista ja monipuolista dataa tekoälyratkaisuillesi.


