
Tekoäly edistää ihmisen kaltaista vuorovaikutusta tietokonejärjestelmien kanssa, kun taas koneoppimisen avulla nämä koneet voivat oppia jäljittelemään ihmisälyä jokaisessa vuorovaikutuksessa. Mutta mikä toimii näissä erittäin kehittyneissä ML- ja AI-työkaluissa? Tietojen huomautus.
Data on ML-algoritmeja käyttävä raaka-aine – mitä enemmän dataa käytät, sitä parempi tekoälytuote on. Vaikka on äärimmäisen tärkeää päästä käsiksi suuriin tietomääriin, on yhtä tärkeää varmistaa, että ne on merkitty tarkasti, jotta saavutettaisiin toteuttamiskelpoisia tuloksia. Tietojen merkintä on edistyneen, luotettavan ja tarkan ML-algoritmisen suorituskyvyn takana oleva datavoimalaitos.
Tietojen merkinnän rooli tekoälykoulutuksessa
Tietojen annotaatiolla on keskeinen rooli ML-koulutuksessa ja tekoälyprojektien yleisessä menestyksessä. Se auttaa tunnistamaan tietyt kuvat, tiedot, tavoitteet ja videot ja merkitsee ne, jotta koneen on helpompi tunnistaa kuvioita ja luokitella tietoja. Se on ihmisen johtama tehtävä, joka kouluttaa ML-mallin tekemään tarkkoja ennusteita.
Jos tietojen merkintää ei suoriteta tarkasti, ML-algoritmi ei voi liittää attribuutteja objekteihin helposti.
Annotoidun harjoitusdatan merkitys tekoälyjärjestelmille
Tietojen merkintä mahdollistaa ML-mallien tarkan toiminnan. Tietojen merkintöjen tarkkuuden ja tarkkuuden ja tekoälyprojektin onnistumisen välillä on kiistaton yhteys.
Globaalin tekoälyn markkina-arvon, jonka arvioidaan olevan 119 miljardia dollaria vuonna 2022, ennustetaan saavuttavan $ 1,597 miljardia 2030, kasvaa 38 % CAGR:llä kauden aikana. Vaikka koko tekoälyprojekti käy läpi useita kriittisiä vaiheita, datamerkintävaiheessa projektisi on merkittävimmässä vaiheessa.
Tietojen kerääminen datan vuoksi ei auta paljon projektiasi. Tarvitset valtavia määriä korkealaatuista, relevanttia dataa toteuttaaksesi tekoälyprojektisi onnistuneesti. Noin 80 % ML-projektien kehittämistyöstäsi kuluu dataan liittyviin tehtäviin, kuten merkitsemiseen, puhdistamiseen, aggregointiin, tunnistamiseen, täydentämiseen ja merkintöihin.
Tietojen merkitseminen on yksi alue, jolla ihmisillä on etulyöntiasema tietokoneisiin verrattuna, koska meillä on synnynnäinen kyky tulkita aikomuksia, kahlata läpi epäselvyyksiä ja luokitella epävarmoja tietoja.
Miksi tietojen merkintä on tärkeää?
Tekoälyratkaisusi arvo ja uskottavuus riippuvat suurelta osin mallikoulutukseen käytetyn datan laadusta.
Kone ei voi käsitellä kuvia kuten me; heitä on koulutettava tunnistamaan malleja koulutuksen avulla. Koska koneoppimismallit sopivat monenlaisiin sovelluksiin – kriittisiin ratkaisuihin, kuten terveydenhuoltoon ja autonomisiin ajoneuvoihin –, joissa kaikilla datamerkintöjen virheillä voi olla vaarallisia seurauksia.
Tietojen merkintä varmistaa, että tekoälyratkaisusi toimii täydellä teholla. ML-mallin kouluttaminen tulkitsemaan ympäristöään tarkasti kuvioiden ja korrelaatioiden avulla, tekemään ennusteita ja ryhtymään tarvittaviin toimiin vaatii erittäin luokiteltua ja huomautettua harjoitustiedot. Annotaatio näyttää ML-mallille vaaditun ennusteen merkitsemällä, transkriptoimalla ja merkitsemällä tietojoukon tärkeitä ominaisuuksia.
Valvottu oppiminen
Ennen kuin syvennymme datamerkintöihin, puretaan datamerkinnät ohjatun ja valvomattoman oppimisen avulla.
Koneoppimisen ohjatun koneoppimisen alaluokka osoittaa tekoälymallikoulutuksen hyvin merkityn tietojoukon avulla. Valvotussa oppimismenetelmässä osa tiedoista on jo merkitty tarkasti ja merkitty. ML-malli, kun se altistuu uudelle tiedolle, käyttää harjoitustietoja saadakseen tarkan ennusteen merkittyjen tietojen perusteella.
Esimerkiksi ML-mallia harjoitellaan kaapin päällä, joka on täynnä erilaisia vaatteita. Ensimmäinen askel koulutuksessa olisi kouluttaa malli erityyppisillä vaatteilla käyttämällä kunkin kankaan ominaisuuksia ja ominaisuuksia. Koulutuksen jälkeen kone pystyy tunnistamaan yksittäiset vaatekappaleet aikaisempaa tietoaan tai koulutusta soveltaen. Ohjattu oppiminen voidaan luokitella luokitukseen (kategorian perusteella) ja regressioon (todellisen arvon perusteella).
Kuinka datamerkintä vaikuttaa tekoälyjärjestelmien suorituskykyyn
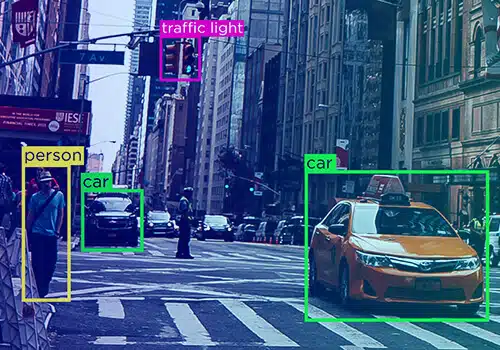 Data ei koskaan ole yksittäinen kokonaisuus – se saa eri muotoja – tekstiä, videota ja kuvaa. Sanomattakin on selvää, että datamerkintöjä on eri muodoissa.
Data ei koskaan ole yksittäinen kokonaisuus – se saa eri muotoja – tekstiä, videota ja kuvaa. Sanomattakin on selvää, että datamerkintöjä on eri muodoissa.
Jotta kone voisi ymmärtää ja tunnistaa tarkasti eri entiteetit, on tärkeää korostaa Nimettyjen entiteettien merkitsemisen laatua. Yksi virhe merkinnöissä ja merkinnöissä, eikä ML pystynyt erottamaan Amazonia – verkkokauppaa, jokea vai papukaijaa.
Lisäksi tietojen merkintä auttaa koneita tunnistamaan hienovaraiset tarkoitukset – laatu, joka tulee luonnostaan ihmisille. Kommunikoimme eri tavalla, ja ihmiset ymmärtävät sekä eksplisiittisesti ilmaistuja ajatuksia että implisiittisiä viestejä. Esimerkiksi sosiaalisen median vastaukset tai arvostelut voivat olla sekä myönteisiä että negatiivisia, ja ML:n tulisi ymmärtää molemmat. 'Mahtava paikka. Vierailee uudelleen.' Se on positiivinen lause, vaikka "Mikä hieno paikka se olikaan! Rakastimme tätä paikkaa! on negatiivinen, ja ihmisen tekeminen voi tehdä tästä prosessista paljon helpompaa.

Haasteet datamerkinnöissä ja niiden voittaminen
Kaksi päähaastetta tietojen merkinnässä ovat hinta ja tarkkuus.
Erittäin tarkkojen tietojen tarve: AI- ja ML-projektien kohtalo riippuu annotoidun datan laadusta. ML- ja AI-malleihin on syötettävä johdonmukaisesti hyvin luokiteltua dataa, joka voi kouluttaa mallin tunnistamaan muuttujien välisen korrelaation.
Suurien tietomäärien tarve: Kaikki ML- ja AI-mallit viihtyvät suurilla tietojoukoilla – yksi ML-projekti tarvitsee vähintään tuhansia merkittyjä kohteita.
Resurssien tarve: Tekoälyprojektit ovat resurssiriippuvaisia sekä kustannusten, ajan että työvoiman suhteen. Ilman kumpaakaan näistä tietomerkintäprojektisi laatu voi mennä pieleen.
[Lue myös: Videon huomautus koneoppimista varten ]
Tietojen merkintöjen parhaat käytännöt
Tietojen annotoinnin arvo näkyy sen vaikutuksessa tekoälyprojektin lopputulokseen. Jos tietojoukko, jolla harjoittelet ML-mallejasi, on täynnä epäjohdonmukaisuuksia, harhaa, epätasapainoa tai vioittunut, tekoälyratkaisusi voi epäonnistua. Lisäksi, jos tarrat ovat vääriä ja huomautus on epäjohdonmukainen, myös tekoälyratkaisu saa aikaan epätarkkoja ennusteita. Mitkä ovat datamerkintöjen parhaat käytännöt?
Vinkkejä tehokkaaseen ja tehokkaaseen datan merkintään
- Varmista, että luomasi tietotunnisteet ovat tarkkoja ja johdonmukaisia projektin tarpeiden kanssa ja silti riittävän yleisiä kaikkiin mahdollisiin muunnelmiin.
- Merkitse suuria määriä dataa, joita tarvitaan koneoppimismallin kouluttamiseen. Mitä enemmän tietoja kirjoitat, sitä parempi on mallikoulutuksen tulos.
- Tietojen merkintöjä koskevat ohjeet auttavat pitkälle luomaan laatustandardeja ja varmistamaan johdonmukaisuuden koko projektin ja useiden merkintöjen välillä.
- Koska tietojen merkitseminen voi olla kallista ja riippuvaista työvoimasta, on järkevää tarkistaa palveluntarjoajilta valmiiksi merkittyjä tietojoukkoja.
- Tietojen tarkkojen huomautusten ja koulutuksen helpottamiseksi tuo in-the-loop-ihmisen tehokkuus tuodaksesi monimuotoisuutta ja käsitelläksesi kriittisiä tapauksia sekä merkintäohjelmiston ominaisuuksia.
- Aseta laatu tärkeysjärjestykseen testaamalla annotaattorit laadun vaatimustenmukaisuuden, tarkkuuden ja johdonmukaisuuden suhteen.
Laadunvalvonnan merkitys huomautusprosessissa
 Laadukkaat datamerkinnät ovat tehokkaiden tekoälyratkaisujen elinehto. Hyvin merkityt tietojoukot auttavat tekoälyjärjestelmiä toimimaan moitteettomasti jopa kaoottisessa ympäristössä. Samoin päinvastoin on yhtä totta. Tietojoukko, joka on täynnä merkintöjen epätarkkuuksia, tuo esiin epäjohdonmukaisia ratkaisuja.
Laadukkaat datamerkinnät ovat tehokkaiden tekoälyratkaisujen elinehto. Hyvin merkityt tietojoukot auttavat tekoälyjärjestelmiä toimimaan moitteettomasti jopa kaoottisessa ympäristössä. Samoin päinvastoin on yhtä totta. Tietojoukko, joka on täynnä merkintöjen epätarkkuuksia, tuo esiin epäjohdonmukaisia ratkaisuja.
Joten kuvan laadun valvonnalla, videoiden merkinnöillä ja huomautusten tekemisessä on merkittävä rooli tekoälyn tuloksessa. Korkealaatuisten valvontastandardien ylläpitäminen koko merkintäprosessin ajan on kuitenkin haastavaa pienille ja suurille yrityksille. Riippuvuutta erityyppisistä merkintätyökaluista ja monipuolisesta merkintätyövoimasta voi olla vaikea arvioida ja ylläpitää laadun yhdenmukaisuutta.
Hajautetun tai etätyöskentelyn datamerkintälaitteiden laadun ylläpitäminen on vaikeaa, etenkin niille, jotka eivät tunne vaadittuja standardeja. Lisäksi vianmääritys tai virheen korjaaminen voi viedä aikaa, koska se on tunnistettava hajautetulle työvoimalle.
Ratkaisu olisi kouluttaa annotaattorit, ottaa mukaan valvoja tai se, että useat datan annotaattorit tarkastelevat ja tarkistavat vertaisjoukon merkintöjen tarkkuutta. Lopuksi testaa säännöllisesti annotaattorien tietämystä standardeista.
Annotaattorien rooli ja kuinka valita oikeat kommentaattorit tiedoillesi
Ihmisen annotaattoreilla on avain onnistuneeseen tekoälyprojektiin. Tietojen annotaattorit varmistavat, että tiedot on merkitty tarkasti, johdonmukaisesti ja luotettavasti, koska ne voivat tarjota kontekstin, ymmärtää tarkoituksen ja luoda perustan tietojen pohjatotuuksille.
Osa tiedoista merkitään keinotekoisesti tai automaattisesti automaatioratkaisujen avulla kohtuullisen luotettavasti. Voit esimerkiksi ladata Googlesta satoja tuhansia kuvia taloista ja tehdä niistä tietojoukoksi. Tietojoukon tarkkuus voidaan kuitenkin määrittää luotettavasti vasta mallin käynnistyttyä.
Automaattinen automaatio saattaa tehdä asioista helpompaa ja nopeampaa, mutta kiistatta vähemmän tarkkaa. Toisaalta ihmisen annotaattori voi olla hitaampi ja kalliimpi, mutta ne ovat tarkempia.
Ihmistietojen kirjoittajat voivat merkitä ja luokitella tietoja aiheen asiantuntemuksensa, synnynnäisen tietämyksensä ja erityiskoulutuksensa perusteella. Tietojen annotaattorit varmistavat tarkkuuden, tarkkuuden ja johdonmukaisuuden.
[Lue myös: Aloittelijan opas tietomerkintöihin: vinkkejä ja parhaita käytäntöjä ]
Yhteenveto
Tehokkaan tekoälyprojektin luomiseksi tarvitset korkealaatuisia selitettyjä harjoitustietoja. Vaikka hyvin merkittyjen tietojen johdonmukainen hankkiminen voi olla aikaa ja resursseja – jopa suurille yrityksille – ratkaisu löytyy vakiintuneiden datamerkintäpalveluntarjoajien, kuten Shaipin, palveluista. Shaipilla autamme sinua skaalaamaan tekoälykykyäsi datamerkintäasiantuntijapalveluidemme avulla vastaamaan markkinoiden ja asiakkaiden kysyntään.


