
Digitaalisessa maailmassamme yritykset käsittelevät tonnia dataa päivittäin. Data pitää organisaation käynnissä ja auttaa sitä tekemään parempia päätöksiä. Yritykset ovat täynnä asiakirjoja, aina uusia luovia työntekijöitä asiakirjoihin, jotka saapuvat organisaatioon eri lähteistä, kuten sähköposteista, portaaleista, laskuista, kuiteista, hakemuksista, ehdotuksista, reklamaatioista ja muista lähteistä.
Ellei joku tarkista näitä asiakirjoja, ei voida tietää, mistä tietystä asiakirjasta on kyse tai mikä on paras tapa käsitellä sitä. Jokaisen asiakirjan manuaalinen käsittely sen selvittämiseksi, missä ja miten se tulisi säilyttää, on kuitenkin vaikeaa.
Tutkitaan asiakirjojen luokittelua, ymmärretään, miksi asiakirjojen luokittelu on elintärkeää yritykselle, ja tutkitaan, kuinka tietokonenäkö, luonnollisen kielen käsittely ja optinen merkintunnistus vaikuttavat asiakirjojen luokitukseen tai asiakirjojen käsittelyyn.
Mikä on asiakirjaluokitus?
Manuaaliset asiakirjojen luokittelutehtävät voivat olla valtava pullonkaula monille yrityksille, koska ne ovat aikaa vieviä, virhealttiita ja resursseja vieviä. Kun käytetään automaattisia NLP- ja ML-luokitusmalleja, asiakirjan teksti tunnistetaan, merkitään ja luokitellaan automaattisesti.
Asiakirjojen luokittelutehtävät perustuvat yleensä kahteen luokitukseen: tekstiin ja visuaaliseen. Tekstin luokittelu perustuu sisällön genren, teeman tai tyypin mukaan. Luonnollisen kielen käsittelyä käytetään tekstin käsitteen, tunteiden ja kontekstin ymmärtämiseen. Visuaalinen luokittelu tehdään dokumentissa olevien visuaalisten rakenteellisten elementtien perusteella käyttämällä Computer Visionia ja kuvantunnistusjärjestelmiä.
Miksi yritykset vaativat asiakirjojen luokittelua?

Jokainen suuri ja pieni yritys joutuu käsittelemään dokumentaatiota hallitakseen jokapäiväistä toimintaansa. Koska jokaista asiakirjaa on mahdotonta käsitellä manuaalisesti, on tarpeen käyttää automaattista dokumenttien luokittelujärjestelmää. Asiakirjojen luokittelujärjestelmän avulla yritykset voivat järjestää sisältöä ja asettaa sen saataville milloin tahansa.
Asiakirjojen luokittelulla on useita käyttötapauksia eri toimialoilla sairaaloista yrityksiin.
- Se auttaa yrityksiä automatisoimaan asiakirjojen hallinnan ja käsittelyn.
- Asiakirjojen luokittelu on arkipäiväinen ja toistuva tehtävä, prosessin automatisointi vähentää käsittelyvirheitä ja nopeuttaa läpimenoaikaa.
- Asiakirjojen automatisointi parantaa myös tehokkuutta, luotettavuutta ja skaalautuvuutta.
Asiakirjojen luokittelu vs. Tekstin luokitus
Tekstin luokittelua ja asiakirjaluokitusta käytetään joskus vaihtokelpoisina. Vaikka näiden kahden välillä on hyvin pieni ero, on tärkeää tietää, miten ne eroavat toisistaan.
Tekstiluokittelu on kyse tekniikoiden käyttämisestä tekstin analysointiin tekstipohjaisissa asiakirjoissa. Teksti voidaan luokitella eri tasoille, kuten
| Lauseen taso | Alalauseen taso |
|---|---|
| Tekstin luokittelu perustuu yhden lauseen tietoihin. | Alilausetaso vetää osalausekkeita lauseiden sisältä. |
| Kappaletaso | Asiakirjan taso |
|---|---|
| Poimii ydintiedot tai tärkeimmät tiedot yhdestä kappaleesta. | Piirrä tärkeät tiedot koko asiakirjasta. |
Tekstin luokittelu on asiakirjaluokituksen osajoukko, joka käsittelee kokonaan missä tahansa asiakirjassa olevan tekstin luokittelua. Vaikka tekstin luokittelu koskee vain tekstiä, asiakirjan luokittelu on sekä tekstiä että visuaalista. Tekstin luokittelussa vain tekstiä käytetään luokitteluun, kun taas dokumenttien luokittelussa koko asiakirjaa voidaan käyttää kontekstina.
Miten asiakirjaluokitus toimii?
Asiakirjojen luokittelu voidaan tehdä kahdella tavalla: manuaalinen ja automaattinen. Manuaalisessa luokittelussa ihmisen on tarkasteltava asiakirjoja, löydettävä käsitteiden välisiä suhteita ja luokiteltava sen mukaan. Automaattisessa dokumenttien luokittelussa käytetään koneoppimista ja syväoppimistekniikoita. Selvitetään asiakirjojen luokittelumenetelmiä ymmärtämällä erityyppisiä asiakirjoja ja liiketoimintaprosesseja.
Strukturoidut asiakirjat
Asiakirja sisältää hyvin muotoiltua dataa, jossa on johdonmukainen numerointi ja fontit. Myös asiakirjan asettelu on johdonmukainen eikä siinä ole poikkeamia. Luokittelutyökalujen rakentaminen tällaisille strukturoiduille asiakirjoille on helppoa ja ennustettavaa.
Strukturoimattomat asiakirjat
Strukturoimattoman asiakirjan sisältö on esitetty jäsentelemättömässä tai avoimessa muodossa. Esimerkkejä ovat kirjeet, sopimukset ja tilaukset. Koska ne ovat epäjohdonmukaisia, kriittisen tiedon löytäminen on haastavaa.

Asiakirjojen luokitustekniikat?
Automaattinen asiakirjojen luokittelu käyttää koneoppimis- ja luonnollisen kielenkäsittelytekniikoita luokitteluprosessin yksinkertaistamiseksi, automatisoimiseksi ja nopeuttamiseksi. Koneoppiminen tekee asiakirjojen luokituksesta vähemmän hankalaa, nopeampaa, tarkempaa, skaalautuvaa ja puolueetonta.
Asiakirjojen luokittelu voidaan tehdä kolmella tekniikalla. He ovat
Sääntöön perustuva tekniikka
Sääntöpohjainen tekniikka perustuu kielellisiin malleihin ja sääntöihin, jotka antavat ohjeita mallille. Mallit on koulutettu tunnistamaan kielimalleja, morfologiaa, syntaksia, semantiikkaa ja paljon muuta tekstin merkitsemiseksi. Tätä tekniikkaa voidaan jatkuvasti parantaa, lisätä uusia sääntöjä ja improvisoida tarkkoja oivalluksia. Tämä tekniikka voi kuitenkin olla aikaa vievä, skaalautumaton ja monimutkainen.
Ohjattu oppiminen
Valvotussa oppimisessa määritellään joukko tunnisteita, ja useat tekstit merkitään manuaalisesti, jotta koneoppimisjärjestelmä voi oppia tekemään tarkkoja ennusteita. Algoritmi opetetaan manuaalisesti joukkoon merkittyjä asiakirjoja. Mitä enemmän tietoja syötät järjestelmään, sitä parempi lopputulos. Jos tekstissä lukee esimerkiksi "Palvelu oli edullinen", tagin tulisi olla "hinnoittelu" -kohdan alla. Kun mallin koulutus on valmis, se voi automaattisesti ennustaa näkymättömiä asiakirjoja.
Valvomaton oppiminen
Ohjaamattomassa oppimisessa samanlaiset asiakirjat ryhmitellään eri klustereihin. Tämä oppiminen ei vaadi aiempaa tietoa. Asiakirjat luokitellaan fonttien, teemojen, mallien ja muiden perusteella. Jos säännöt ovat ennalta määriteltyjä, muokattuja ja viimeisteltyjä, tämä malli voi tarjota luokituksen tarkasti.
Asiakirjojen luokitteluprosessi
Automaattisen asiakirjojen luokittelualgoritmin rakentaminen sisältää syväoppimisen ja koneoppimisen työnkulkuja.
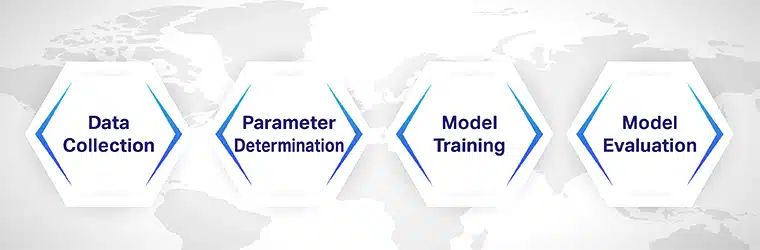
Vaihe 1: Tiedonkeruu
Tiedonkeruu on ehkä tärkein vaihe asiakirjojen luokittelualgoritmien koulutuksessa. On tarpeen kerätä asiakirjoja eri luokista, jotta algoritmi voi oppia luokittelemaan ne.
Jos mallisi on esimerkiksi luokiteltava viiteen eri luokkaan, sinulla on oltava tietojoukko, joka sisältää vähintään 300 asiakirjaa luokkaa kohden.
Varmista myös, että koulutuksessa käyttämäsi tietojoukko on merkitty oikein. Jos tietojoukko on virheellinen, rakentamasi malli on täynnä ongelmia.
Vaihe 2: Parametrien määritys
Ennen mallin kouluttamista sinun on määritettävä parametrit koneoppimismallien kouluttamiseksi. Tässä vaiheessa määrittämiäsi mittareita voidaan muokata, jotta mallista tulee tarkempi ja luotettavampi sen ennusteissa.
Vaihe 3: Mallikoulutus
Parametrien asettamisen jälkeen malli on koulutettava. Jos olet vasta aloittamassa mallinkehitystä, voit kokeilla avoimen lähdekoodin tietojoukkojen käyttöä koulutus- ja testaustarkoituksiin.
Jos malli yleensä toimii koneoppimisalgoritmin kanssa, voit tuoda mallin tai suorittaa koodauksen algoritmin logiikan perusteella.
Vaihe 4: Mallin arviointi
Mallin arviointi koulutuksen jälkeen on välttämätöntä sen tehokkuuden ja tarkkuuden parantamiseksi. Aloita jakamalla tietojoukko kahteen laajaan osaan, joista toinen on koulutusta ja toinen testausta varten. Käytä 70 % tietojoukosta mallin harjoittamiseen ja loput 30 % testaukseen ja arviointiin.
Tosielämän käyttötapaukset
Asiakirjojen luokittelua käytetään useiden liiketoimintaongelmien ratkaisemiseen. Vaikka useimmat käyttötapaukset eivät ole luokittelutehtäviä, algoritmia käytetään useiden tosielämän ongelmien ratkaisemiseen.
Roskapostin tunnistus
Asiakirjojen luokittelua, erityisesti tekstiluokitusta, käytetään ei-toivotun roskapostin havaitsemiseen. Malli on koulutettu tunnistamaan roskapostilauseet ja niiden tiheys sen määrittämiseksi, onko viesti roskapostia. Esimerkiksi Googlen Gmailin roskapostin tunnistin käyttää Natural Language Processing -tekniikkaa havaitakseen usein esiintyvät sanat roskaviesteissä ja pudottaakseen sähköpostin oikeaan kansioon.
Aistien analyysi
Sentimenttianalyysi sosiaalisen kuuntelun avulla auttaa yrityksiä ymmärtämään asiakkaitaan, heidän mielipiteitään ja arvostelujaan. Luokittelemalla arvostelut, palautteet ja valitukset ja luokittelemalla ne emotionaalisen luonteensa perusteella NLP-pohjaiset mallit auttavat tunteiden analysoinnissa. Malli on koulutettu poimimaan sanoja, jotka merkitsevät tai joilla on positiivisia tai negatiivisia konnotaatioita.
Lippu tai prioriteettiluokitus
Minkä tahansa yrityksen asiakaspalvelu kohdata monia palvelupyyntöjä ja lippuja. Automaattinen asiakirjojen luokittelutyökalu voi auttaa kahlaamaan läpi valtavan määrän lippuja. NLP:n avulla prioriteettiliput voidaan reitittää oikealle osastolle. Tämä parantaa merkittävästi resoluution, käsittelyn ja huollon nopeutta.
Objektien tunnistaminen
Automaattista dokumenttien luokittelua käytetään myös suurten määrien visuaalisen datan käsittelyyn asiakirjoissa luokittelemalla ne luokkien mukaan. Objektintunnistusta käytetään tyypillisesti verkkokaupassa tai tuotantoyksiköissä tuotteiden luokittelemiseen.
Dokumenttien luokituksen käytön aloittaminen Tekoälyn avulla
Asiakirjat sisältävät yrityksen toiminnan kannalta kriittistä tietoa. Dokumentit sisältävät arvokkaita oivalluksia, jotka edistävät organisaation toimintaa, palveluita ja kasvutavoitteita.
Asiakirjojen luokittelu on kuitenkin työlästä mutta tarpeellista. Koska asiakirjojen luokittelu on haaste, varsinkin jos volyymi on suhteellisen suuri, tarvitaan automaattinen asiakirjojen luokittelujärjestelmä.
Koneoppimisalgoritmeilla koulutettu tekoälypohjainen dokumenttien luokittelumalli on tehokas, kustannustehokas, virheetön ja tarkka. Prosessi voi kuitenkin käynnistyä vain, kun rakentamasi malli on koulutettu käyttämään laadukkaita ja tarkasti merkittyjä tietojoukkoja.
Shaip tuo sinulle esimerkityt tietojoukot jotka auttavat kehittämään tarkkoja luokitusmalleja. Ota meihin yhteyttä ja aloita dokumenttien luokittelutyökalusi käyttö heti.


